-

在Python中打开文件使用utf-8-sig和utf-8的区别
今天在使用Python读取CSV文件的时候,出现了一个KeyError的错误的,这个错误提示很明显,就是没有对应的列名,但是经过检查我的CSV文件中是有对应的列名的呀,然后编码格式我也检查了,这个时候我就想先打印列名看下,打印后就看出问题了。 问题原因 假设通过Excel打开我的CSV文件,列名是:列名1、列名2... 但是打印出的结果是如下: ['\ufeff列名1', &#…... 塵風
塵風- 0
- 0
- 923
-
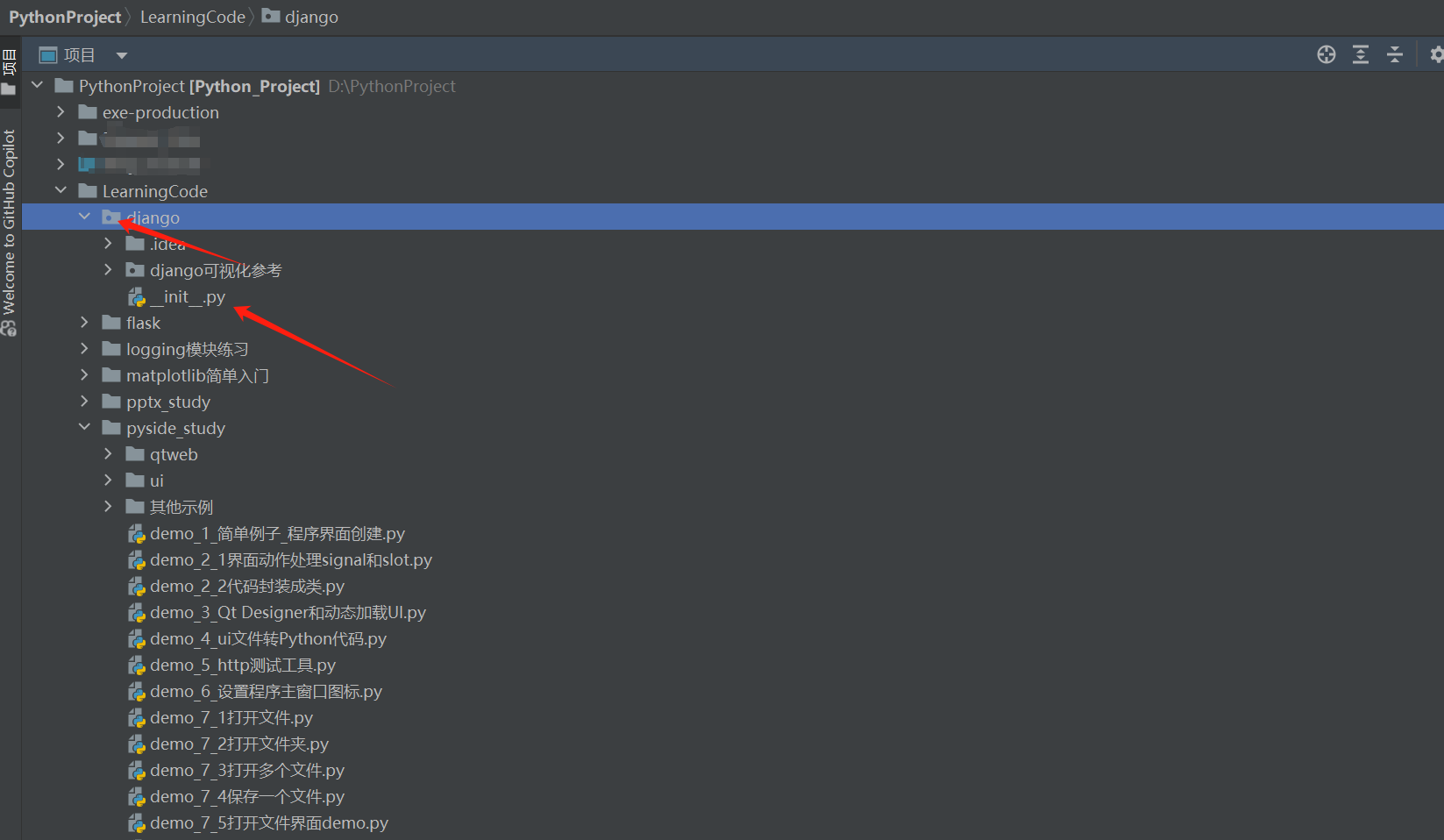
Pycharm项目目录文件夹图标小圆点代表什么意思
Pycharm项目目录文件夹图标小圆点代表什么意思:带小圆点的目录则代表这是一个Python的包,这个目录里面会有__init__.py文件。 如下图所示: 带点和不带点区别 带有小圆点的文件夹目录是packkage,即Python的包,里面会有__init__.py文件 没有点的是一个directory,即是普通的文件夹 在文件夹添加或者删除__init__.py文件,它就会变成包或者普通文件夹…...- 塵風
- 0
- 0
- 1.2k
-
Pycharm如何选中多行编辑
Pycharm如何选中多行编辑: 快捷键 同时选中多行快捷键:ctrl + shift +alt +点击鼠标左键 操作流程 按住后可以在任意需要的位置增加光标 然后就可以松开,进行下一步操作: 如果是同时操作(如光标在代码之间移动),则 ctrl + 上下左右键 如果是同时选中光标附近的代码,则 ctrl + shift + 上下左右键 如下图,我们选中的行前面都会有光标闪烁显示: 然后就可以对这…...- 塵風
- 0
- 0
- 1.1k
-
Python reversed 函数 – 对序列进行逆序操作
Python reversed 函数是一个Python内置函数,它可以对序列进行逆序操作。 序列可以是列表、元组、字符串等,通过使用reversed()函数,我们可以快速简便地将序列中的元素进行逆序排列。我们也可以用它来实现for循环反向遍历。 reversed()函数语法 reversed(sequence) 参数 sequence即是要进行逆序操作的序列( tuple, string…...- 塵風
- 0
- 0
- 467
-
Python os.walk() 方法
概述 os.walk() 方法用于通过在目录树中游走输出在目录中的文件名,向上或者向下。 os.walk() 方法是一个简单易用的文件、目录遍历器,可以帮助我们高效的处理文件、目录方面的事情。 在Unix,Windows中有效。 语法 walk()方法语法格式如下: os.walk(top[, topdown=True[, onerror=None[, followlinks=False]]]) …...- 塵風
- 0
- 0
- 1k
-
Python字典按照值(value)的大小进行排序方法
Python字典按照值(value)的大小进行排序可以使用collections的Counter()函数和sorted函数两种方式进行,关于Counter和sorted函数之前也记录过,关于这两个详细的就不说了,有需要可以自己看看: python Counter()函数介绍 - 统计值出现的次数 Python3 sorted() 函数 - 对所有可迭代的对象进行排序操作。 下面我们直接看使用它们对…...- 塵風
- 0
- 0
- 859
-
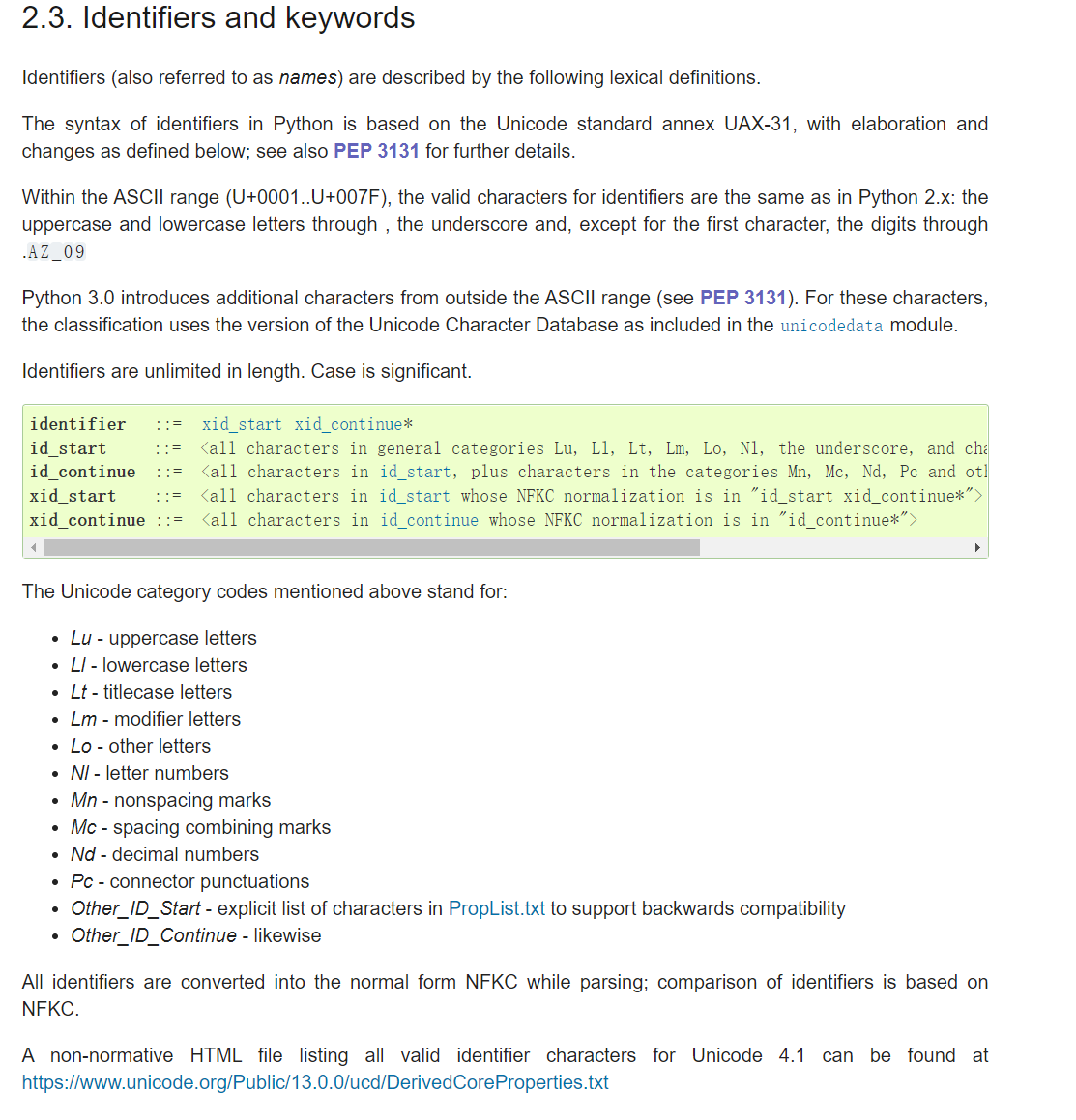
Python支持中文变量名吗?
Python已经支持中文变量名 Python3.x 已经支持全面 Unicode 编码,支持使用中文作为变量名。(支持是支持,实际使用不使用是另外一回事哈哈,有时候用中文会有一些莫名其妙的问题...) 例如: 博主简介 = "博主是个超级无敌大帅哥" print(f"{博主简介}") # 博主是个超级无敌大帅哥 python文档2.3.标识符和关键字截图: …...- 塵風
- 0
- 0
- 1.2k
-
Python列表合并的6种方法
Python列表合并的6种方法分享,下面我共列举了6中合并列表的方法,在单个或者少量(3个内?)我们可以直接使用运算符+或者+=或者extend就可以轻松的实现合并,如果列表数量太多,可以考虑使用chain,详细的介绍和示例代码大家往下看吧。 准备数据 首先我们准备三个列表作为测试学习使用数据,下面的代码中不在重复。 # 以三个全是名字元素的列表作为测试数据 name_list_1 = […...- 塵風
- 0
- 0
- 811

-
¥优惠劵使用时效:无法使用使用时效:
之前
使用时效:永久有效优惠劵ID:×