-

Python for循环同时遍历两个列表
Python for循环同时遍历两个列表我们可以使用Python zip函数来实现, zip() 函数简介 zip() 函数是 Python 内置函数之一,zip() 函数用于将可迭代的对象作为参数,将对象中对应的元素打包成一个个元组,然后返回由这些元组组成zip对象。 在Python2中,zip() 函数返回的是列表,在Python3中,则是返回上述所说的zip对象,这样可以减少内存。如果需要列…... 塵風
塵風- 0
- 0
- 520
-

Windows python安装教程(超详细)
1:下载python python官网地址:https://www.python.org/ python下载地址直达:https://www.python.org/downloads/ 由于国内网络特殊原因,去官网下载不科学上网可能会很慢或者无法下载。 这里附上国内华为python安装包地址: 华为python安装包下载地址:https://mirrors.huaweicloud.com/pyth…...- 塵風
- 0
- 0
- 1.7k
-
使用Python批量检查网站友情链接
外链对SEO的重要性到今天我想已经不用多说了,友情链接则是我们在优化过程中毕竟经常使用的一种增加外链方法,不过外链还是需要定期的检查的,毕竟一些站长下链卖站了可能不一定会提醒...或者有的网站已经不续费了,域名过期被抢注,直接做灰黑产业站点,我们又没下链,那么排名可能就会直接消失..哈哈哈,但是我们网站多了,又不可能一个个人工去检查,像我之前公司以前SEO订单多的时候要优化100+站点,自己又有一…...- 塵風
- 0
- 0
- 557
-
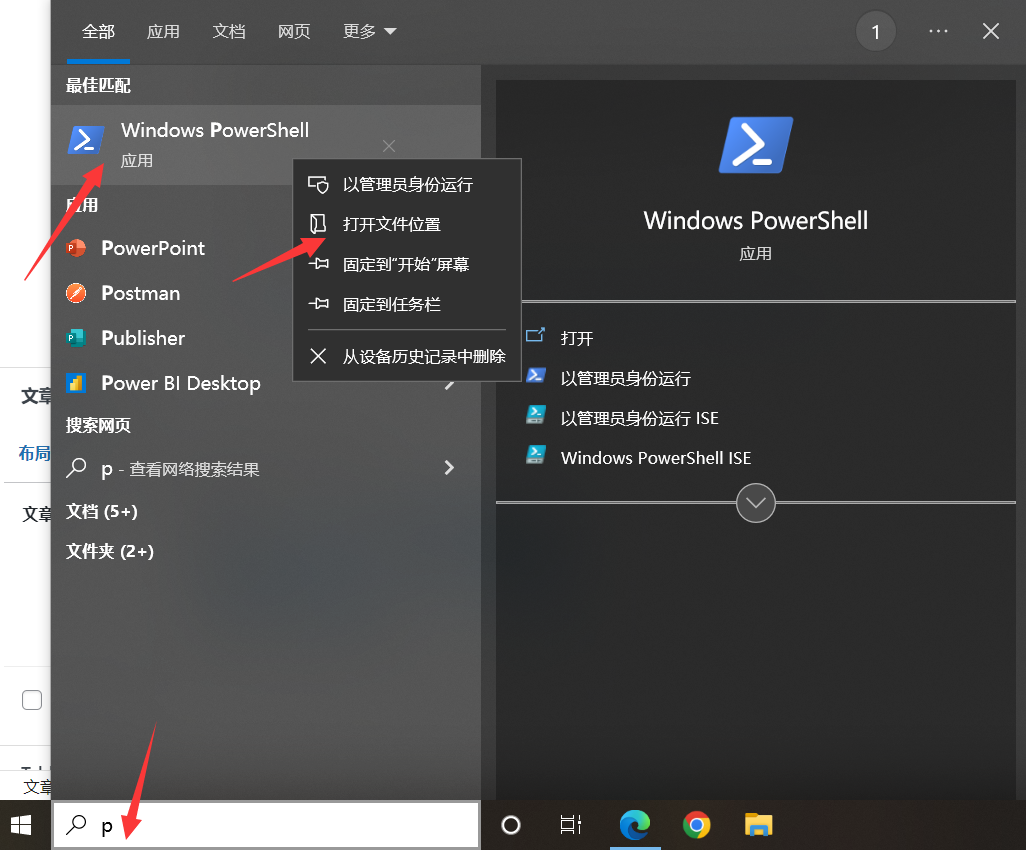
Windows下将Pycharm终端更改为PowerShell
Windows下将Pycharm终端更改为PowerShell:我们都知道power shell不管是从功能上还是性能上都要比CMD要强大得多,我们安装了power shell后,可以将pycharm编辑器中的默认终端切换为power shell,方便我们的使用。 更改流程 1:找到power shell路径 先搜索到我们的power shell,右键,然后选择打开文件位置 打开是几个快捷键:我们…...- 塵風
- 0
- 0
- 2.3k
-
Python requests获取状态码
Python requests获取状态码可以通过status_code获取,例如: r = requests.get('https://httpbin.org/get') print(r.status_code) # 打印状态码 但是:requests默认不会获取301/302状态码。使用上述代码如果请求了一个被301/302跳转的URL,也会返回跳转后的状态码,如果是正常请求…...- 塵風
- 0
- 0
- 1.6k
-
Python字典按照值(value)的大小进行排序方法
Python字典按照值(value)的大小进行排序可以使用collections的Counter()函数和sorted函数两种方式进行,关于Counter和sorted函数之前也记录过,关于这两个详细的就不说了,有需要可以自己看看: python Counter()函数介绍 - 统计值出现的次数 Python3 sorted() 函数 - 对所有可迭代的对象进行排序操作。 下面我们直接看使用它们对…...- 塵風
- 0
- 0
- 870
-
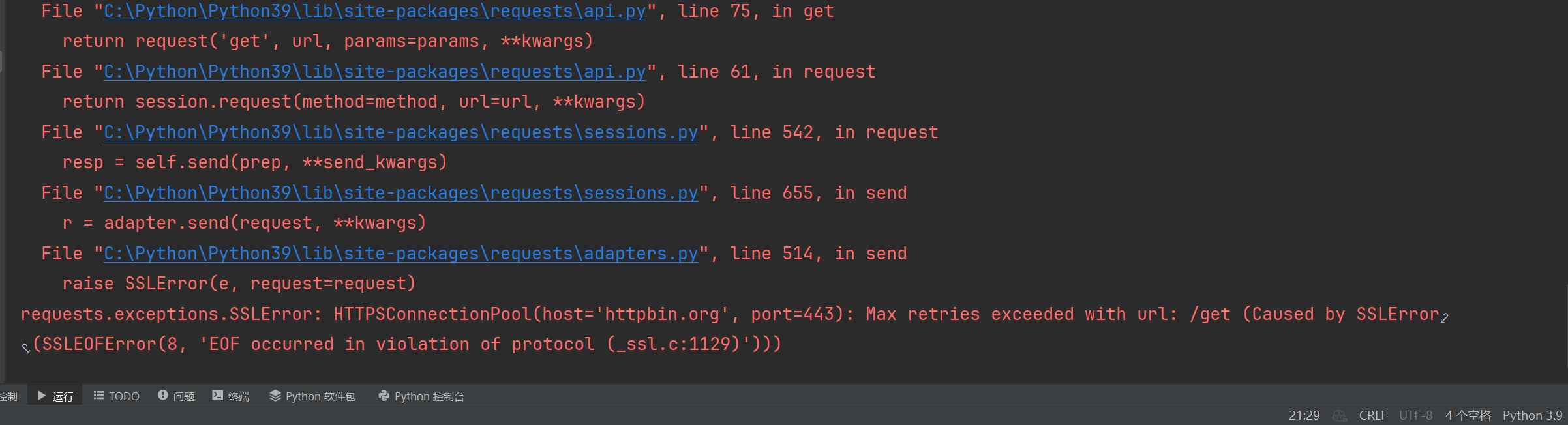
Python爬虫报错:(Caused by SSLError(SSLEOFError(8, ‘EOF occurred in violation of protocol (_ssl.c:1129)’)))解决
今天在写爬虫的时候遇到一个错误,即: requests.exceptions.SSLError: HTTPSConnectionPool(host='httpbin.org', port=443): Max retries exceeded with url: /get (Caused by SSLError(SSLEOFError(8, 'EOF occurred …...- 塵風
- 0
- 0
- 17.4k
-
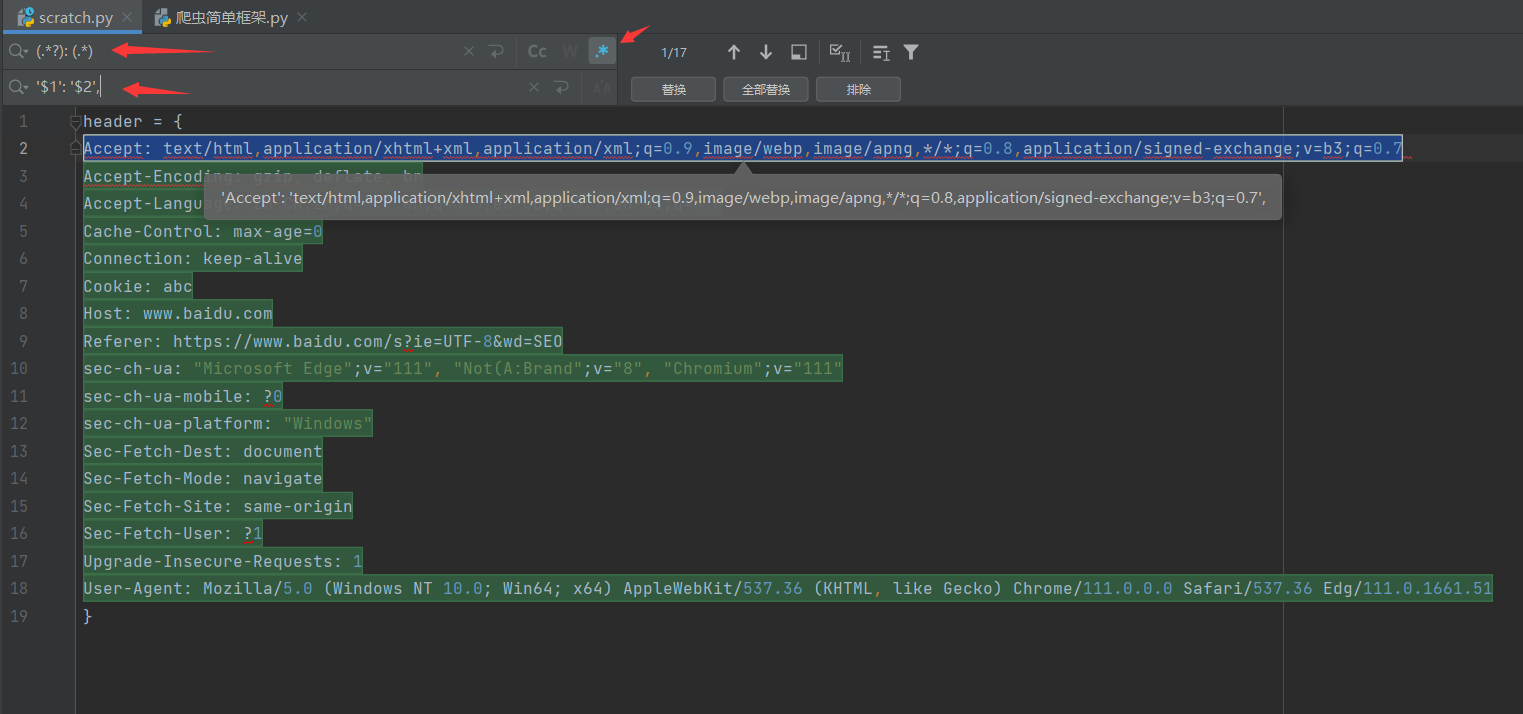
Pycharm批量添加引号
Pycharm批量添加引号和选中多行进行编辑技巧记录分享: Pycharm中批量添加单引号或者是双引号我们可以通过pycharm中的搜索替换中正则表达式功能或者是批量选择多行的方式进行添加,非常简单和高效,在我们写代码的时候可以很好的帮助我们提高效率,不用一个个去点击添加,就比如我们复制浏览器header要做个dict的时候。 PS:网上说Pycharm中有自带的快捷键,我找了下并没有找到,也就没…...- 塵風
- 0
- 0
- 2.2k
-

PyCharm中文指南、教程-百度云免费
今天分享的PyCharm中文文档的相关资源,有相关接触的可以考虑收藏,熟悉编辑器可以有效的帮助我们提高我们的编程效率,在方便新手学习使用的同时在使用中遇到各种Pycharm编辑器相关问题,可以查找帮助解决,以备不时之需! PyCharm是什么,这里就不扯了,点进这里来的我想到都知道PyCharm是什么,文章下面也有一点网上复制过来的pycharm简介,之前也分享过:Pycharm安装详细教程(非常…...- 塵風
- 0
- 0
- 2.2k
-
解决python:AttributeError: ‘set’ object has no attribute ‘items’错误记录
在之前写爬虫代码的时候,我自以为认代码各方面的都没问题了,但是出现了这样一个错误: AttributeError: 'set' object has no attribute 'items' 手动苦笑不得,检查了一遍代码发现都没问题,但是运行还是出现这个错误,于是我就果断百度了下, 出现这个错误可能是我们把一组dict,用逗号相隔了 例如{“id”,id}应…...- 塵風
- 0
- 0
- 2.4k
-

Python入门学习资料推荐
我一直有建议身边和网上的一些朋友学Python(Python的应用范围很广,会编程可以很好的提高我们的工作效率,对一些工作进行批量、自动化的处理),再加上肯定也有一些网上的小伙伴想学习不会找或者是想找合适的资料的,我以后也要分享Python相关的东西,在这之前就先把这个入门的问题解决了,今天就顺便推荐下我觉得好的Python入门学习资料。 下面我推荐的教程主要推荐是黑马程序员和白月黑羽这两家的。 …...- 塵風
- 0
- 0
- 709
-
Python实现将字符串复制到粘贴板
Python实现将字符串复制到粘贴板方法分享: 一:使用perclip库 安装 pip install pyperclip 示例代码 # 导入pyperclip import pyperclip # 使用pyperclip.copy()方法可以将指定的字符串复制到剪贴板。 text = '这是要复制到剪贴板的文本' pyperclip.copy(text) # 运行代码后 Ct…...- 塵風
- 0
- 0
- 1.2k
-
Python reversed 函数 – 对序列进行逆序操作
Python reversed 函数是一个Python内置函数,它可以对序列进行逆序操作。 序列可以是列表、元组、字符串等,通过使用reversed()函数,我们可以快速简便地将序列中的元素进行逆序排列。我们也可以用它来实现for循环反向遍历。 reversed()函数语法 reversed(sequence) 参数 sequence即是要进行逆序操作的序列( tuple, string…...- 塵風
- 0
- 0
- 484
-
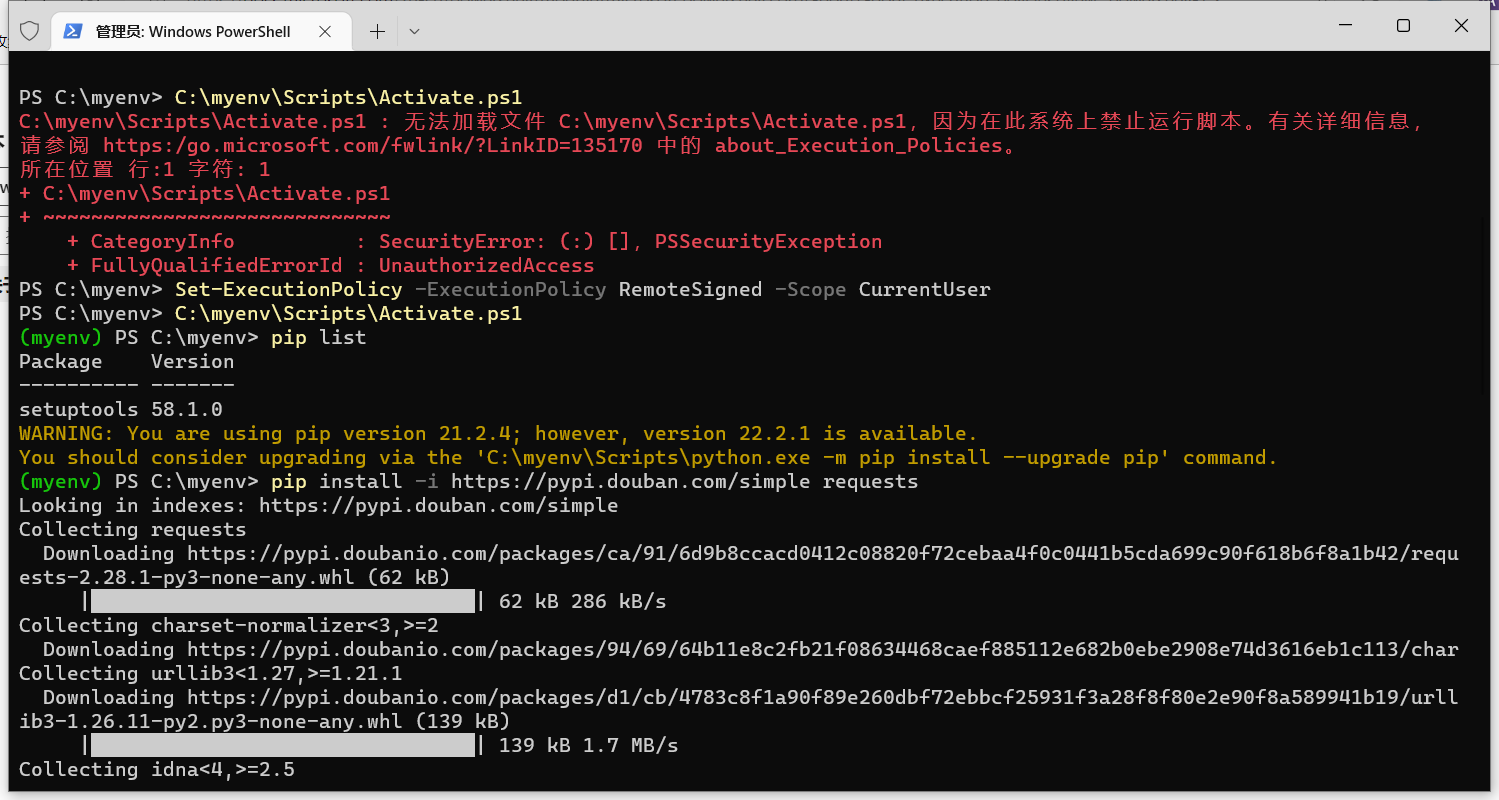
power shell 激活python虚拟环境报错:无法加载文件 *.ps1,因为在此系统上禁止运行脚本。有关详细信息,请参阅 …
在使用python虚拟环境的时候,使用power shell 激活虚拟环境的过程中,出现报错: 报错信息 无法加载文件 *.ps1,因为在此系统上禁止运行脚本。有关详细信息,请参阅 https:/go.microsoft.com/fwlink/?LinkID=135170 中的 about_Execution_Policies。 解决方案 管理员打开PowerShell执行Set-Executio…...- 塵風
- 0
- 0
- 2.3k
-

Python拼接URL:urllib.parse urljoin使用
Python拼接URL可以使用urllib.parse中的urljoin方法,urllib是Python中一个用于URL 处理的模块,urllib.parse 用于解析 URL,在之前分享的Python从路径|URL中获取文件名、文件后缀的方法中提到过使用其中的urlparse方法解析URL,感兴趣的可以去看看。 urllib.parse模块的的urlparse和urljoin刚好是两个相反的功能…...- 塵風
- 0
- 0
- 1.1k
-
Pycharm函数注释(参数和返回值)无法自动生成问题解决
正常使用Pycharm,对定义的函数书写注释(三个引号),Pycharm是会自动生成函数参数和返回值的注释格式,如下: 问题展示 # 定义一个函数 def test(a, b): """ # 再输入三个引号(单引号和双引号均可)后回车,会自动生成函数参数和返回值的注释 pass 正常情况: 输出结果为 def test(a, b): '''…...- 塵風
- 0
- 0
- 1.9k
-
Python从列表中随机获取元素方法
Python从列表中随机获取元素方法:可以使用python中random模块的sample, choice, choices,randint方法来进行。下面我们一起来看下四种从列表中随机获取元素方法: sample random.sample(sequence, k) sample的作用是从指定序列中随机获取指定长度的片断并随机排列,结果以列表的形式返回。 注意:sample函数不会修改原有序列(…...- 塵風
- 0
- 0
- 5.7k
-
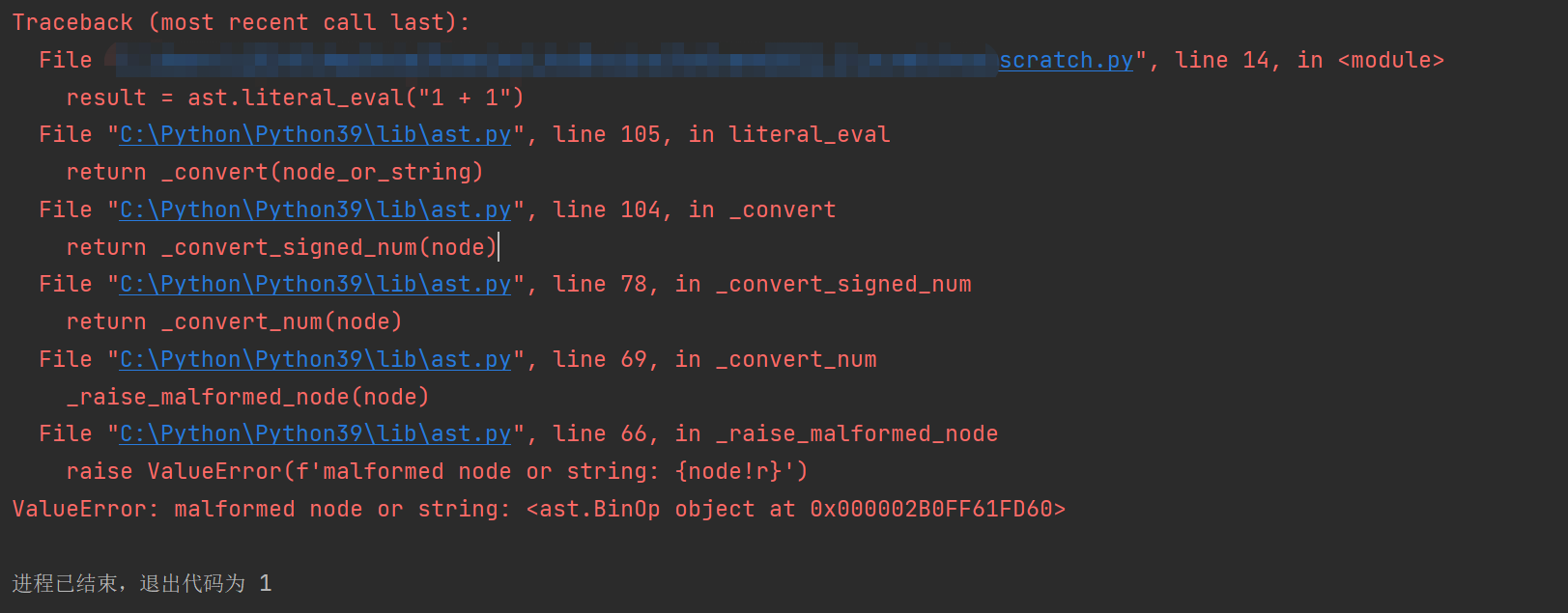
Python 将字符串转为字典
Python 将字符串转为字典可以使用ast模块中的literal_eval方法或者是json模块、eval方法。下面分享下这三种方法的示例代码: 注:虽然上面列举了三个在Python中可以实现将字符串转为字典的方法,但是推荐使用ast模块中的literal_eval方法进行,具体的原因会在下述说明,下面是详细的代码: 通过 json 来转换 我们可以直接使用json模块中的loads函数对字符串…...- 塵風
- 0
- 0
- 768
-
Python获取字典的前x个元素
Python获取字典的前*个元素我们可以使用itertools中的islice函数实现或者是sorted函数、Counter(dict).most_common()函数实现,再Python中列表实现这样的需求就很简单,我们可以直接通过切片获取,不过字典没有切片,我们就先取出所有 keys,再用拿到的key去取value,在组成一个新的字典就可以了。 注意: sorted函数、Counter(dic…...- 塵風
- 0
- 0
- 1.1k
-
PyCharm破解教程(简单长期稳定)
PyCharm破解教程(简单长期稳定)分享,本人重装系统后需要重新安装很多东西,pycharm就是其中一个,下面分享下pycharm的破解教程。如果你也想重装系统的话,可以点这里查看我分享的教程:简单快速重装windows纯净原版操作系统教程(无需U盘无需设置Bios) 注意:本文所分享的内容已经有较长时间了,具体是否可用博主已经不确定了,如果还需要使用旧版本pycharm的小伙伴可以试试,不然建…...- 塵風
- 0
- 0
- 4k

-
¥优惠劵使用时效:无法使用使用时效:
之前
使用时效:永久有效优惠劵ID:×