-

WordPress程序Robots文件写法建议
Robots简介 robots协议(也称为爬虫协议、爬虫规则、机器人协议等)也就是robots.txt,网站通过robots协议告诉搜索引擎哪些页面可以抓取,哪些页面不能抓取。 Robots协议是网站国际互联网界通行的道德规范,其目的是保护网站数据和敏感信息、确保用户个人信息和隐私不被侵犯。因其不是命令,故需要搜索引擎自觉遵守。一些病毒如malware(马威尔病毒)经常通过忽略robots协议的方…... 塵風
塵風- 0
- 0
- 1.2k
-
SEO新人理解误区:收录、权重代表一个网站价值、站长水平
写这篇文章主要是收到一个评论,啊哈哈哈。 原因应该是我SEO培训的推广在其他网站挂了软文,然后我放了我这个博客地址。然后就被找上门来了。(具体哪里我也不知道,因为其实挺多个网站放了广告的,部分是朋友的,部分让朋友帮我买的) 这种人以此来看,有几个问题,一是素质不够,二是认知不够,三是自以为是。 为什么这么说呢? 首先,我做我的,我也没影响别人,你也没资格说这说那,而且还爆粗口,由此可见教养也不怎样…...- 塵風
- 0
- 0
- 1.2k
-
相似度计算常用方法综述
引言 相似度计算用于衡量对象之间的相似程度,在数据挖掘、自然语言处理中是一个基础性计算。其中的关键技术主要是两个部分,对象的特征表示,特征集合之间的相似关系。在信息检索、网页判重、推荐系统等,都涉及到对象之间或者对象和对象集合的相似性的计算。而针对不同的应用场景,受限于数据规模、时空开销等的限制,相似度计算方法的选择又会有所…...- 塵風
- 0
- 0
- 1.2k
-
SEO优化技巧:导航栏“首页”链接处理技巧
网站SEO优化,我们的网站结构是非常是重要的,通常来讲,一个页面越早出现的链接,能够获得的权重也越高,导航栏菜单是我们基本每个网站的都会有的,我们通常用于放至一些比较的重要的页面和栏目,而在导航栏上面,通常第一个出现的,都是我们的首页按钮,但是首页这个按钮并不是我们想要的目标关键词呀。 如果把首页这个按钮替换成其他的,大部分网站都容易给用户造成体验下降的情况,那么针对这种情况,我们应该如何处理我们…...- 塵風
- 0
- 0
- 1.1k
-
下载1个资源
 下载1个资源
下载1个资源
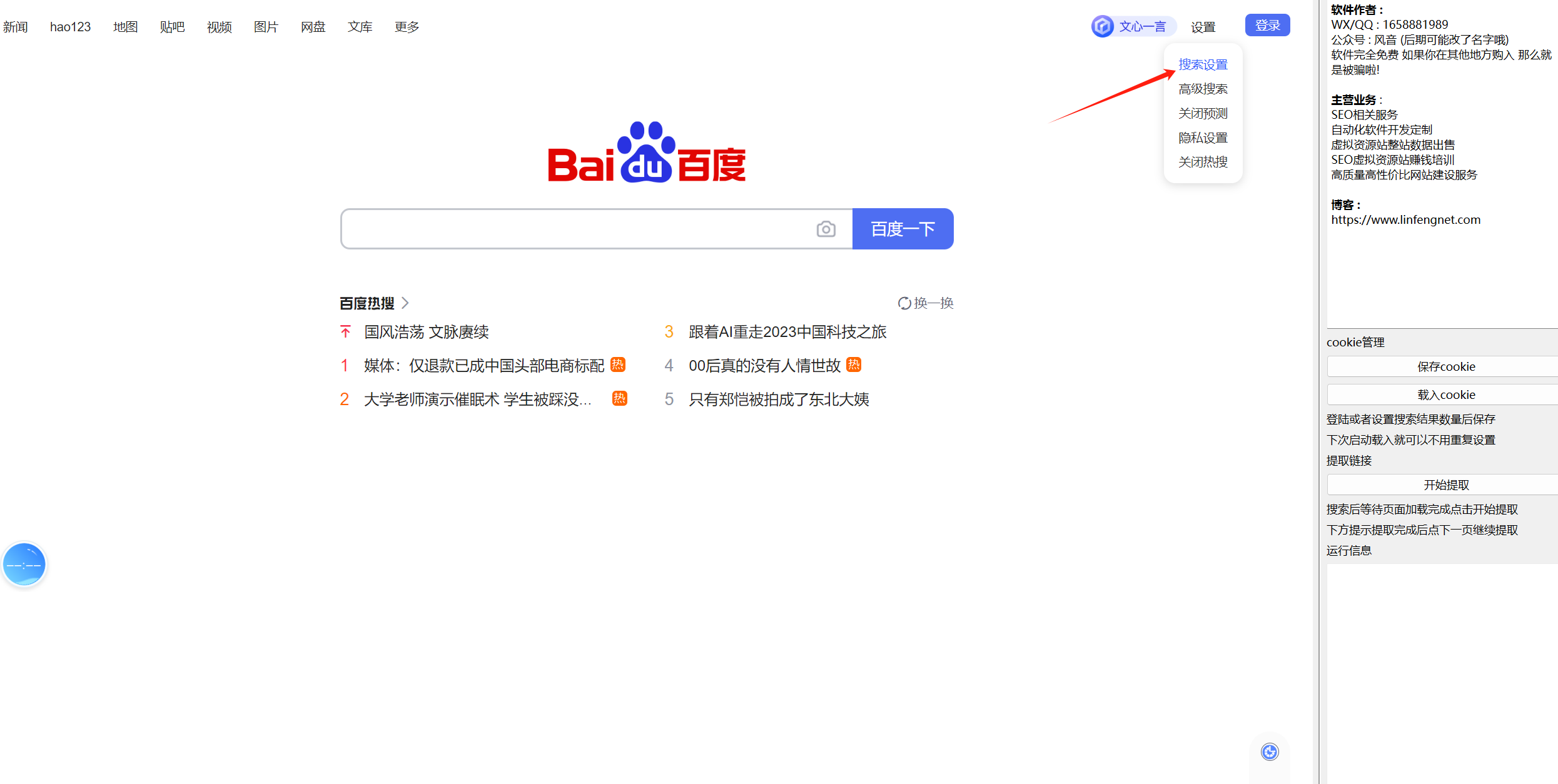
百度已收录404链接自动提取软件+使用教程-免费
软件介绍 现在有非常多的网站被黑然后搜索被搜索引擎收录了色情赌博一类的垃圾信息,我们站点被黑处理完成后把这些垃圾信息链接设置为404就需要对这些已经收录的链接进行提取,然后提交到百度资源平台删除,但是对于大部分没有技术基础的小伙伴来说,都只能一个个手动去复制,这样太过于麻烦了,所有开发了这个软件分享给大家。 关于处理流程的教程,我之前也分享了相关文章,如果你有需要,也可以查看: 网站被黑,被搜索引…...- 塵風
- 0
- 6
- 1k
-
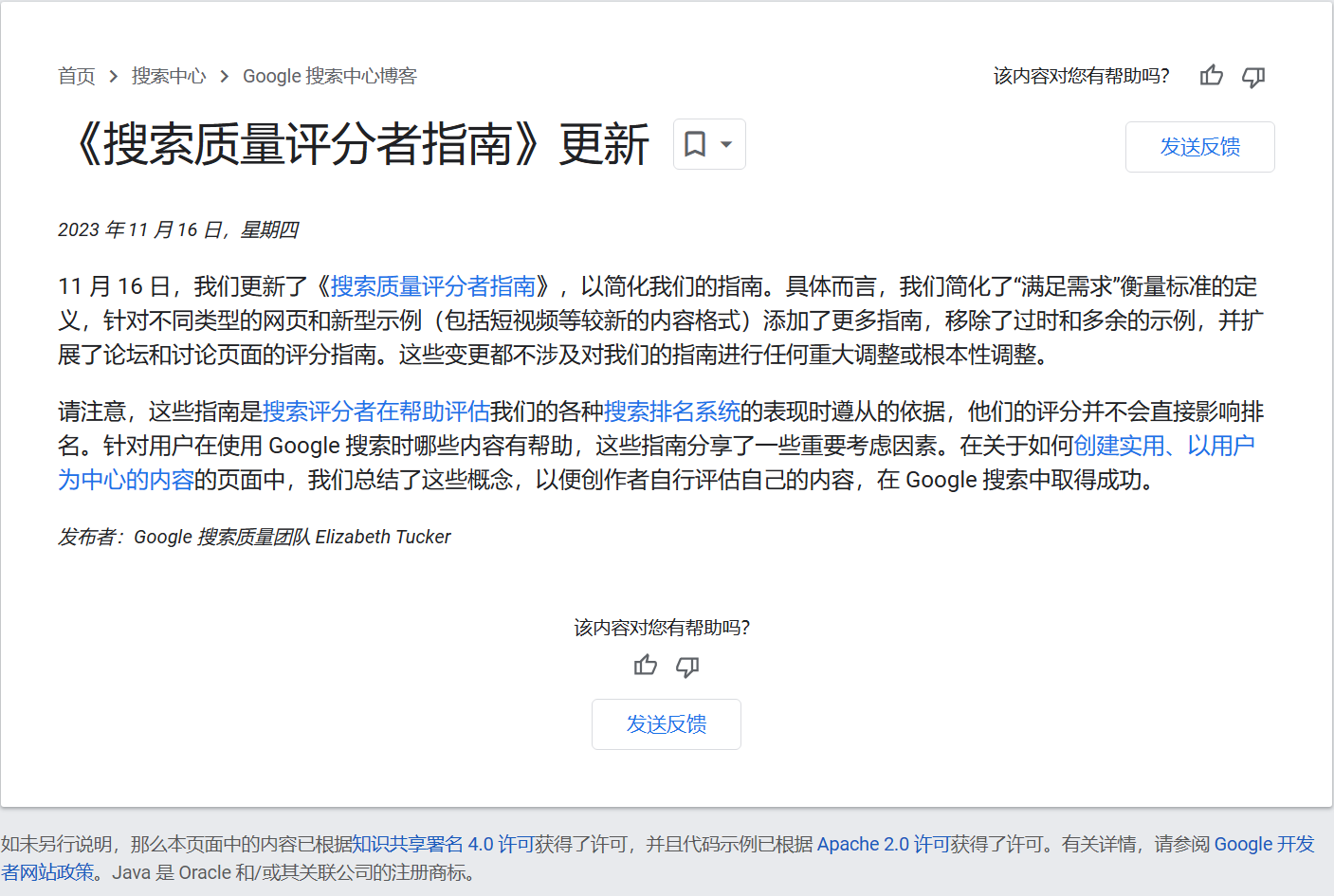
Google搜索质量评分者指南下载-2023年11月16日更新
搜索引擎官方推出的资料通常都是建议大家去阅读学习的, 例如: 搜索引擎优化 (SEO) 新手指南, Google搜索质量评分者指南等...英文资料可以搜索网上的解读文章以及利用chatgpt等工具, 总之方法很多 这里不多赘述...下面是更新信息: Google 搜索中心博客在2023年11月16日推出信息更新了搜索质量评分者指南, 下面是原文内容: 11 月 16 日,我们更新了《搜索质量评分者…...- 塵風
- 0
- 0
- 1k
-
让搜索跨越语言的鸿沟——谈跨语言信息检索技术
跨语言信息检索,是信息检索领域中的一个研究课题。近10几年来,由于互联网的飞速发展,这方面的研究受到了学术界的广泛重视。将这项技术应用于搜索,可以帮助我们查找到更多的有用信息,例如外语相关页面、多语言页面以及语言无关的资源(如图片)等等。这些信息可以大大丰富搜索的结果,满足用户多样的需求。在跨语言信息检索的研究中,有一些研究成果已经趋于成熟,达到可以应用的状态。事实上,Yahoo和Google在5…...- 塵風
- 0
- 0
- 1k
-
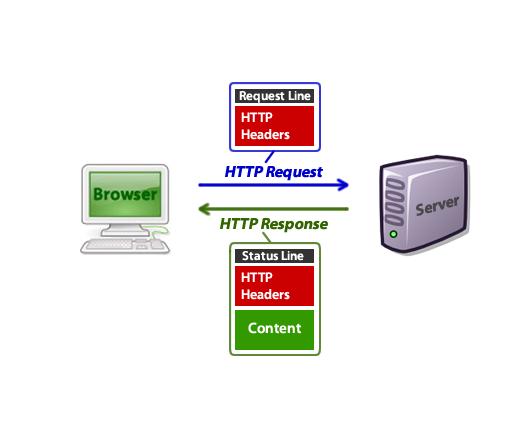
如何根据http请求信息区分访问用户的国家、语言信息
是不是见到google,facebook等大型专业网站的拥有不同的语言站群,可以不同语言间切换很给力?而我们只能羡慕嫉妒恨呢? 今天要介绍的就是如何识别不同国家,只需要简单几步,就能识别出来自不同国家的请求,使你的web应用更有国际范。 国家识别主要用到的是http header中的host,Accept-Language,cookie以及请求的url,ip等。 下面先温习下http header…...- 塵風
- 0
- 0
- 1k
-
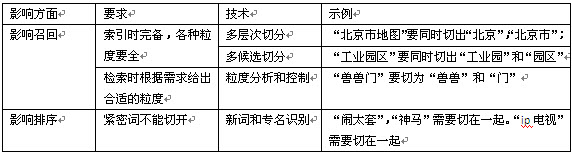
搜索引擎中的粒度问题
一.前言 传统的搜索引擎的定义,是指一种对于指定的查询(Query),能够返回与之相关的文档集合(Documents)的系统。而百度将这个定义更加丰富化,即搜索引擎能够帮助人们更方便的找到所求。这里的“所求”,比“文档”更加宽泛和丰富,比如一个关于天气的查询,直接返回一个天气预报的窗口,而非一篇关于天气的文档;再如一个关于小游戏的查询,直接返回这个小游戏的Flash页面而非简单的介绍性的文字。 百…...- 塵風
- 0
- 0
- 1k
-
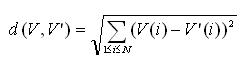
若无云,岂有风——词语语义相似度计算简介
诸多事物都要受到其周边事物的影响,进而改变自身的形态,甚至确立自己的存在——云动,方知风的存在。反映在人的眼中,则是云赋予了风的含义:若无云,岂有风? 0. 动机 武林高手经常从山川之间顿悟,并由山川之形变化出上乘武艺。风云之间的飘渺互动,实则也为实打实的科学、工程实践提供了指引。风是客观存在的,而只有籍由云,我们才能观察到它。在技术领域的日常工作中,诸如此类的例子数不胜数。而在自然语言语义的研究…...- 塵風
- 0
- 0
- 983
-
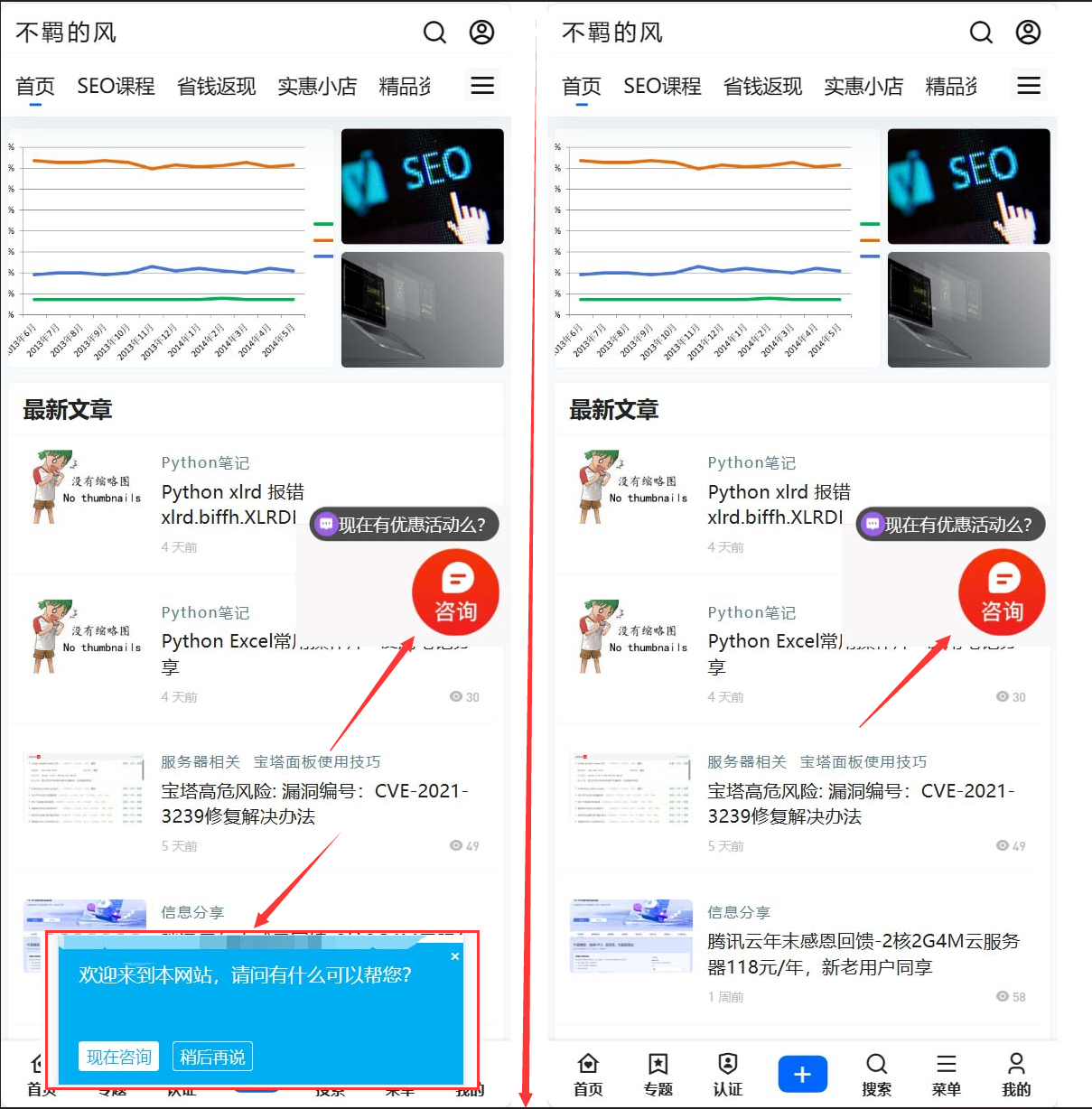
网站体验优化:自适应站点移动/PC页面分别设置爱番番弹窗
用户体验这点无论是搜索引擎还是我们,都是需要非常注意的一个点,下面我就来说一个做搜索推广中的一个小技巧,就是关于百度爱番番这个客服工具的: 在自适应网站启用了爱番番沟通工具,开启了邀约弹窗之后,pc端看起来没啥,但是移动端触发了这个弹窗就很难看,对用户的友好度也很低。特别是部分朋友开启了每隔多少秒就触发的,而且是时间间隔比较短的那种估计很容易让用户反感(如果客服不在线的时候就会一直弹出留言窗口),…...- 塵風
- 0
- 0
- 941
-
基于hash计算的多层实验流量切分的实现
1. 背景介绍 站点新功能或者是站内新策略开发完毕之后,在全流量上线之前要评估新功能或者新策略的优劣,常用的评估方法是A-B测试,做法是在全量中抽样出两份小流量,分别走新策略分支和旧策略分支,通过对比这两份流量下的各指标的差异,我们可以评估出…...- 塵風
- 0
- 0
- 935
-
Robots Meta标签
什么是Robots meta标签 Robots.txt文件主要是限制整个站点或者目录的搜索引擎访问情况,而Robots Meta标签则主要是针对一个个具体的页面。 关于robots.txt文件的详解介绍,可以点击这里了解:robots协议文件作用以及写法详解。 和其他的 META标签(如使用的语言、页面的描述、关键词等)一样,Robots Meta标签也是放在页面中,专门用来告诉搜索引擎ROBOT…...- 塵風
- 0
- 0
- 927
-

SEO优化技巧:首页链接nofollow
这个技巧还是我以前在阅读Zac《SEO实战密码》中学习到的,我个人认为实际上并不会有太多的作用(可能以前有用吧,具体未知,当下而言这并不重要。)。 之所以的说不重要是国内的SEO发展环境实在是...而且搜索引擎发展至今已经智能的多了。 原文内容: 很多页面上会有多个链接连向同一个URL,比如几乎网站的每个页面上都有多个链接连向首页,顶部logo、顶部导航、左侧导航、页脚、版权声明等处,都可以有链接…...- 塵風
- 0
- 0
- 922
-
一种基于flex的可视化多层流量切分界面的实现
1. 背景介绍 策略开发人员在完成策略之后,在全流量上线之前要评估新的策略的优劣,常用的评估方法是A-B测试,做法是在全流量中抽样出两份小流量,分别走新策略分支和旧策略分支,通过对比这两份流量下的各指标的差异,我们可以评估出新策略的优劣,进而…...- 塵風
- 0
- 0
- 911
-
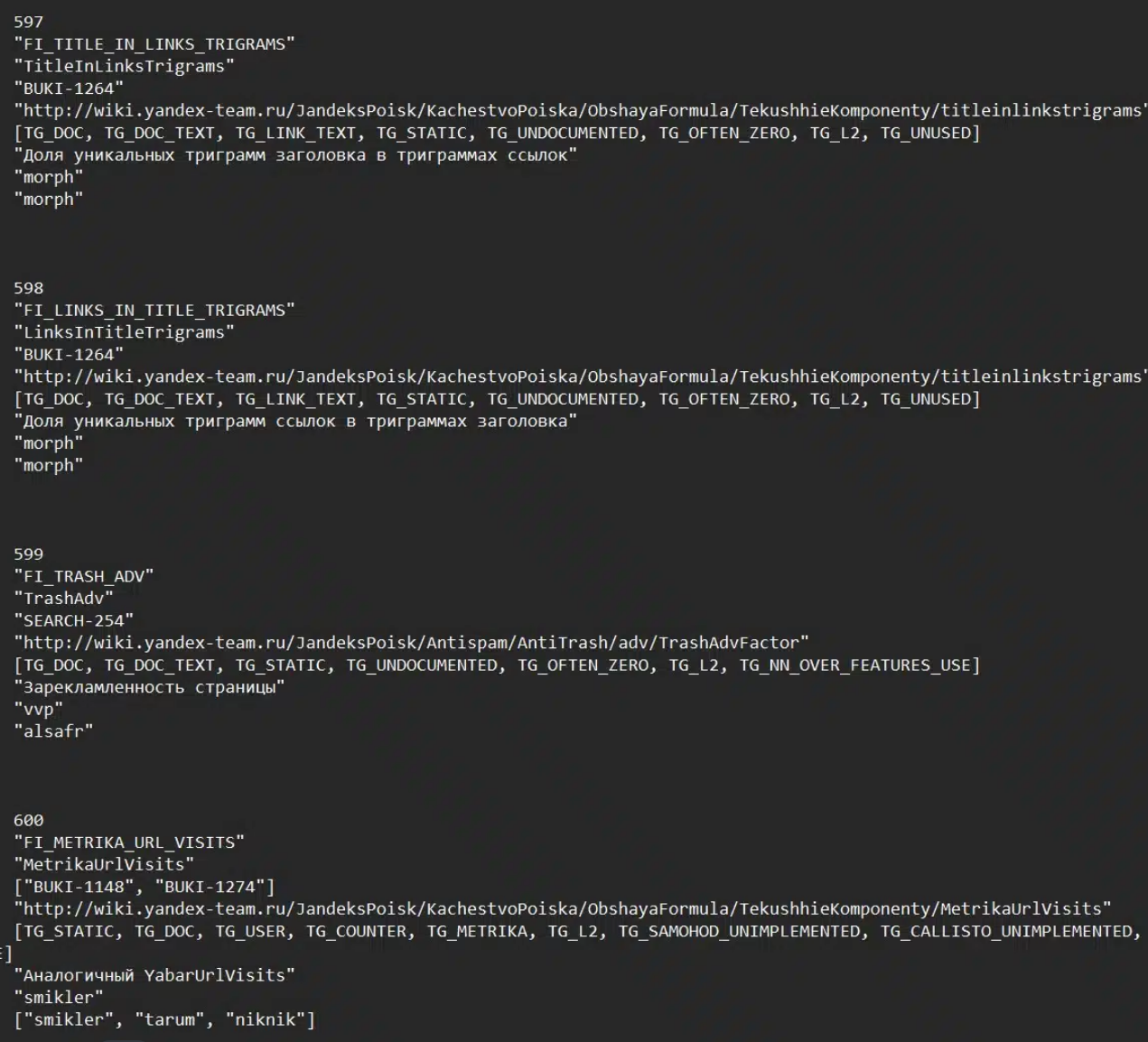
Yandex 搜索引擎源代码泄露1900+排名因子
2023 年 01 月,Yandex 的源代码在一个流行的黑客论坛上泄露。黑客发布了一个7.<> GB的文件,他们声称包含整个源代码减去其反垃圾邮件规则。 这里特别令人着迷的是,它包括一个他们的 1900+ 排名因素文件,供全世界查看。如果你想要下载这个资源,可自行到文章下发的GitHub资源、文档资源这两部分的链接中自行下载。 虽然Yandex不是Google(既它们之间是有区别的)…...- 塵風
- 0
- 0
- 898
-
索引页链接补全机制的一种方法
背景 Spider位于搜索引擎数据流的最上游,负责将互联网上的资源采集到本地,提供给后续检索使用,是搜索引擎的最主要数据来源之一。spider系统的目标就是发现并抓取互联网中一切有价值的网页,为达到这个目标,首先就是发现有价值网页的链接,当前spider有多种链接发现机制来尽量快而全的发现资源链接,本文主要描述其中一种针对特定索引页的链接补全机制,并给出对这种特定类型的索引页面的建议处理规范用于优…...- 塵風
- 0
- 0
- 879


-
¥优惠劵使用时效:无法使用使用时效:
之前
使用时效:永久有效优惠劵ID:×