-

搜索背后的奥秘–浅谈语义主题计算
摘要: 两篇文档是否相关往往不只决定于字面上的词语重复,还取决于文字背后的语义关联。对语义关联的挖掘,可以让我们的搜索更加智能化。本文着重介绍了一个语义挖掘的利器:主题模型。主题模型是对文字隐含主题进行建模的方法。它克服了传统信息检索中文档相似度计算方法的缺点,并且能够在海量互联网数据中自动寻找出文字间的语义主题。近些年来各大互联网公司都开始了这方面的探索和尝试。就让我们看一下究竟吧。 关键词:主…... 塵風
塵風- 0
- 0
- 878
-
智能算法在站点质量评级体系中的应用
互联网的迅速发展,海量Web数据的扑面而来,给搜索引擎技术带来了严峻的挑战,但同时也带来了新的机遇。从网页抓取的角度来看,同一站点往往包含质量相似的资源,对一个优质网站进行爬取,往往可以找到更多的优质资源。因此,我们希望对网站的质量进行评级,来反映资源的质量水平,从而影响spider的调度和收录。在以往的实践中,大体思路是根据人工调研出的经验构造出规则和阈值。发现问题后逐个打补丁、调阈值,来适应变…...- 塵風
- 0
- 0
- 844
-
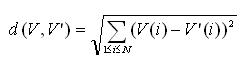
若无云,岂有风——词语语义相似度计算简介
诸多事物都要受到其周边事物的影响,进而改变自身的形态,甚至确立自己的存在——云动,方知风的存在。反映在人的眼中,则是云赋予了风的含义:若无云,岂有风? 0. 动机 武林高手经常从山川之间顿悟,并由山川之形变化出上乘武艺。风云之间的飘渺互动,实则也为实打实的科学、工程实践提供了指引。风是客观存在的,而只有籍由云,我们才能观察到它。在技术领域的日常工作中,诸如此类的例子数不胜数。而在自然语言语义的研究…...- 塵風
- 0
- 0
- 991
-

Boosting算法简介
一、Boosting算法的发展历史 Boosting算法是一种把若干个分类器整合为一个分类器的方法,在boosting算法产生之前,还出现过两种比较重要的将多个分类器整合为一个分类器的方法,即boostrapping方法和bagging方法。我们先简要介绍一下bootstrapping方法和bagging方法。 1)bootstrapping方法的主要过程 主要步骤: i)重复地从…...- 塵風
- 0
- 0
- 791
-

基于hash计算的多层实验流量切分的实现
1. 背景介绍 站点新功能或者是站内新策略开发完毕之后,在全流量上线之前要评估新功能或者新策略的优劣,常用的评估方法是A-B测试,做法是在全量中抽样出两份小流量,分别走新策略分支和旧策略分支,通过对比这两份流量下的各指标的差异,我们可以评估出…...- 塵風
- 0
- 0
- 958
分类描述:
百度搜索研发部官方原介绍:百度搜索研发部官方博客(http://www.baidu-tech.com)由百度搜索研发部创建并维护。我们希望通过网络社区与关注搜索引擎及相关产品的技术人员交流互动,分享百度工程师研究的方向和取得的成果。
注:后貌似在2013年底关停。故而我在互联网中收集整理出部分和搜索引擎相关的内容转发出来,供大家查看。
这些内容对我们了解搜索引擎应该是极具价值的,尤其是当年(那时候我还没接触SEO呢),不过毕竟是时间很长的文章了,现在部分内容在百度资源平台的一些文档中也有提及。

-
¥优惠劵使用时效:无法使用使用时效:
之前
使用时效:永久有效优惠劵ID:×