-

Boosting算法简介
一、Boosting算法的发展历史 Boosting算法是一种把若干个分类器整合为一个分类器的方法,在boosting算法产生之前,还出现过两种比较重要的将多个分类器整合为一个分类器的方法,即boostrapping方法和bagging方法。我们先简要介绍一下bootstrapping方法和bagging方法。 1)bootstrapping方法的主要过程 主要步骤: i)重复地从…... 塵風
塵風- 0
- 0
- 792
-

搜索背后的奥秘–浅谈语义主题计算
摘要: 两篇文档是否相关往往不只决定于字面上的词语重复,还取决于文字背后的语义关联。对语义关联的挖掘,可以让我们的搜索更加智能化。本文着重介绍了一个语义挖掘的利器:主题模型。主题模型是对文字隐含主题进行建模的方法。它克服了传统信息检索中文档相似度计算方法的缺点,并且能够在海量互联网数据中自动寻找出文字间的语义主题。近些年来各大互联网公司都开始了这方面的探索和尝试。就让我们看一下究竟吧。 关键词:主…...- 塵風
- 0
- 0
- 878
-

浅析视频搜索中的清晰度识别过程
一、综述 随着互联网视频越来越多,人们迫切希望能够快速地从众多的视频中精准定位到一些高质量的视频。视频清晰度是评价视频质量的一个重要指标,特别是对于影视剧和动漫类视频来说,高清晰的视频能大大提升用户的体验。所以如何判断视频清晰度,识别出高清晰的视频对于用户和搜索引擎来说是非常有价值的。 和大多数评价机制一样,视频清晰度分为相对清晰度和绝对清晰度。相对清晰度可以理解为视频之间的清晰度排序,而…...- 塵風
- 0
- 0
- 1.3k
-
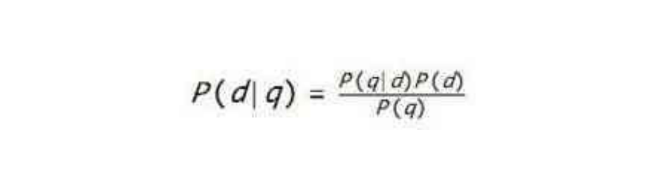
以求医为例谈搜索引擎排序算法的基础原理
我们向搜索引擎提交一个查询,搜索引擎会从先到后列出大量的结果,这些结果排序的标准是什么呢?这个看似简单的问题,却是信息检索专家们研究的核心难题之一。 为了说明这个问题,我们来研究一个比搜索引擎更加古老的话题:求医。比如,如果我牙疼,应该去看怎样的医生呢?假设我只有三种选择: A医生,既治眼病,又治胃病;B医生,既治牙病,又治胃病,还治眼病;C医生,专治牙病。 A医生肯定不在考虑之列。B医生和C医生…...- 塵風
- 0
- 0
- 700
-
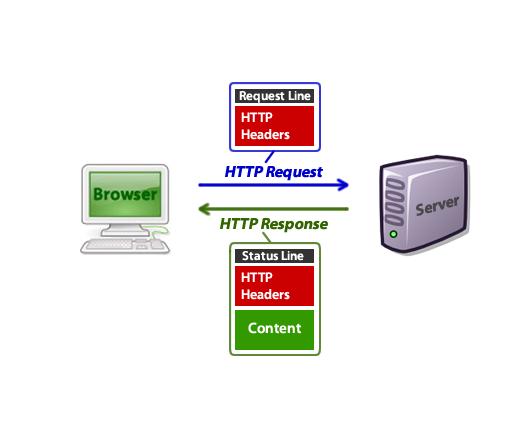
如何根据http请求信息区分访问用户的国家、语言信息
是不是见到google,facebook等大型专业网站的拥有不同的语言站群,可以不同语言间切换很给力?而我们只能羡慕嫉妒恨呢? 今天要介绍的就是如何识别不同国家,只需要简单几步,就能识别出来自不同国家的请求,使你的web应用更有国际范。 国家识别主要用到的是http header中的host,Accept-Language,cookie以及请求的url,ip等。 下面先温习下http header…...- 塵風
- 0
- 0
- 1k
-
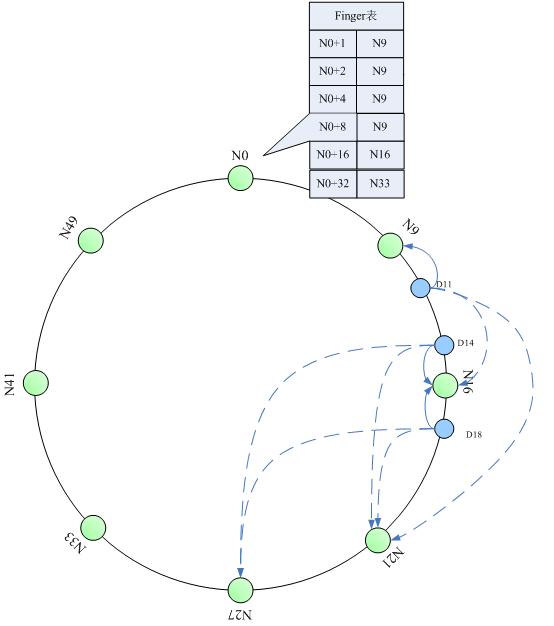
“分布式哈希”和“一致性哈希”的概念与算法实现
分布式哈希和一致性哈希是分布式存储和p2p网络中说的比较多的两个概念了。介绍的论文很多,这里做一个入门性质的介绍。 分布式哈希(DHT) 两个key point:每个节点只维护一部分路由;每个节点只存储一部分数据。从而实现整个网络中的寻址和存储。DHT只是一个概念,提出了这样一种网络模型。并且说明它是对分布式存储很有好处的。但具体怎么实现,并不是DHT的范畴。 一致性哈希: DHT的一…...- 塵風
- 0
- 0
- 741



-
¥优惠劵使用时效:无法使用使用时效:
之前
使用时效:永久有效优惠劵ID:×