-
“分布式哈希”和“一致性哈希”的概念与算法实现
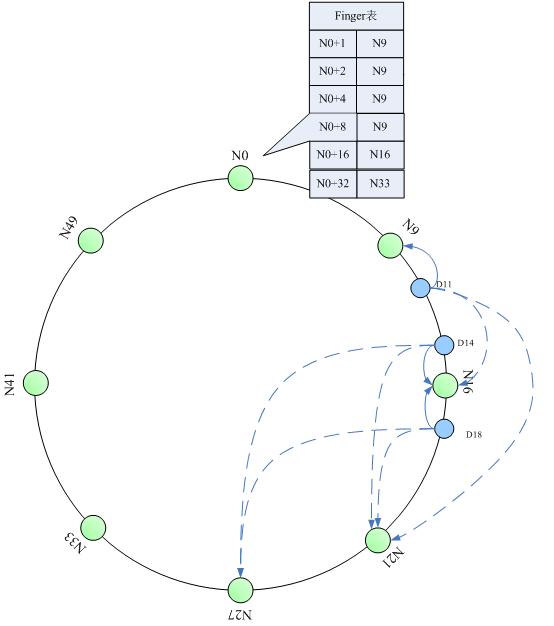
分布式哈希和一致性哈希是分布式存储和p2p网络中说的比较多的两个概念了。介绍的论文很多,这里做一个入门性质的介绍。 分布式哈希(DHT) 两个key point:每个节点只维护一部分路由;每个节点只存储一部分数据。从而实现整个网络中的寻址和存储。DHT只是一个概念,提出了这样一种网络模型。并且说明它是对分布式存储很有好处的。但具体怎么实现,并不是DHT的范畴。 一致性哈希: DHT的一…... 塵風
塵風- 0
- 0
- 741
-
索引页链接补全机制的一种方法
背景 Spider位于搜索引擎数据流的最上游,负责将互联网上的资源采集到本地,提供给后续检索使用,是搜索引擎的最主要数据来源之一。spider系统的目标就是发现并抓取互联网中一切有价值的网页,为达到这个目标,首先就是发现有价值网页的链接,当前spider有多种链接发现机制来尽量快而全的发现资源链接,本文主要描述其中一种针对特定索引页的链接补全机制,并给出对这种特定类型的索引页面的建议处理规范用于优…...- 塵風
- 0
- 0
- 889
-
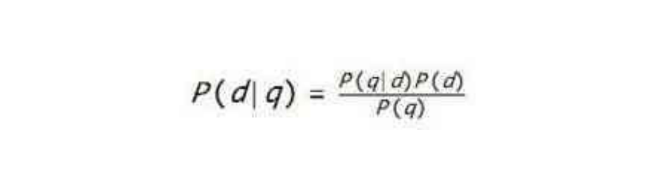
以求医为例谈搜索引擎排序算法的基础原理
我们向搜索引擎提交一个查询,搜索引擎会从先到后列出大量的结果,这些结果排序的标准是什么呢?这个看似简单的问题,却是信息检索专家们研究的核心难题之一。 为了说明这个问题,我们来研究一个比搜索引擎更加古老的话题:求医。比如,如果我牙疼,应该去看怎样的医生呢?假设我只有三种选择: A医生,既治眼病,又治胃病;B医生,既治牙病,又治胃病,还治眼病;C医生,专治牙病。 A医生肯定不在考虑之列。B医生和C医生…...- 塵風
- 0
- 0
- 699
-

语音搜索的基础-语音识别
一直在想,假如有一天我们生活中的机器人像在很多科幻电影里面看到的那样,能够理解人类的语言,并能完成与人类的自然对话,是多爽的事情。语音的研究一直在试图解决这个问题。例如,语音到文字,即通常所说的语音识别,就试图将语音转换为文字,然后交给计算机进行后续的理解;而文字到语音,即语音合成,则试图将文字转换为声音,让人类可以听到。也许通过全世界语音界的科研和工程人员的努力,在不久的将来,我们真的可以和机器…...- 塵風
- 0
- 0
- 611
-
JavaScript解析:让搜索引擎看到更真实的网页
长期以来,站长们选择使用JavaScript来实现网页的动态行为,这样做的原因是多种多样的,如加快页面的响应速度、降低网站流量、隐藏链接或者嵌入广告等。由于早期的搜索引擎没有相应的处理能力,导致在索引这类网页上往往出现问题,可能无法收录有价值的资源,也可能出现作弊。 引入JavaScript解析的目的,正是为了解决上述两方面的问题,其结果也就是使搜索引擎可以更为清晰的了解用户实际打开该网页时看到的…...- 塵風
- 0
- 0
- 790
-

搜索背后的奥秘–浅谈语义主题计算
摘要: 两篇文档是否相关往往不只决定于字面上的词语重复,还取决于文字背后的语义关联。对语义关联的挖掘,可以让我们的搜索更加智能化。本文着重介绍了一个语义挖掘的利器:主题模型。主题模型是对文字隐含主题进行建模的方法。它克服了传统信息检索中文档相似度计算方法的缺点,并且能够在海量互联网数据中自动寻找出文字间的语义主题。近些年来各大互联网公司都开始了这方面的探索和尝试。就让我们看一下究竟吧。 关键词:主…...- 塵風
- 0
- 0
- 878
-
调研分享:Flipboard的使用特点和页面信息抽取机制
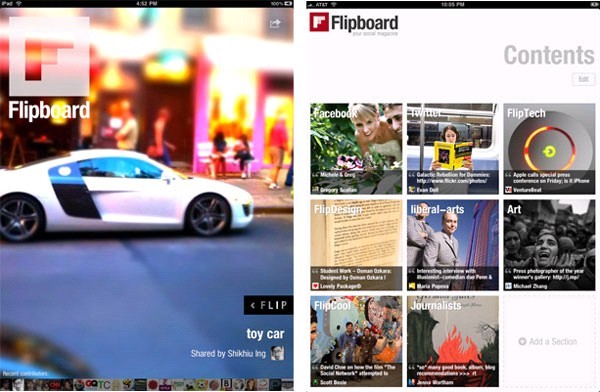
Flipboard是什么? 封面 封面 标榜为“社会化杂志”,是ipad上的app应用,可以订阅twitter和facebook上的人、群组和话题,可以订阅flipboard(后面简称flip)指定的杂志类别,也可以订阅高质量的媒体站点,通过这些渠道,用户可以获得包括新闻、图片、视频、博客、微博等形式的数据,通过触屏点击进行预览、翻屏等操作,操作简单,内容组织图文并茂,类似于传统的杂志。 内容…...- 塵風
- 0
- 0
- 1.3k
-
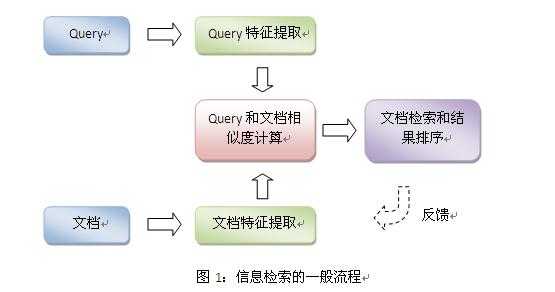
让搜索跨越语言的鸿沟——谈跨语言信息检索技术
跨语言信息检索,是信息检索领域中的一个研究课题。近10几年来,由于互联网的飞速发展,这方面的研究受到了学术界的广泛重视。将这项技术应用于搜索,可以帮助我们查找到更多的有用信息,例如外语相关页面、多语言页面以及语言无关的资源(如图片)等等。这些信息可以大大丰富搜索的结果,满足用户多样的需求。在跨语言信息检索的研究中,有一些研究成果已经趋于成熟,达到可以应用的状态。事实上,Yahoo和Google在5…...- 塵風
- 0
- 0
- 1k
-

基于主特征空间相似度计算的切分算法及切分框架
我们为什么要切分? 说到切分(segmentation),大多数人最容易想到的就是中文分词。作为没有天然空格区分的语言,切词可以帮助计算机去索引文章,从而便于信息检索等方面。该部分主要用到了分词的一个方面:降低搜索引擎的性能消耗。我们常用的汉字有5000多个,常用词组是几十万个。在倒排索引中,如果用每个字做索引的话,那么会造成每个字对应的拉链非常长。所以我们一般会用词组来代替单个汉字建立索引。除此…...- 塵風
- 0
- 0
- 794

-
¥优惠劵使用时效:无法使用使用时效:
之前
使用时效:永久有效优惠劵ID:×