
释放双眼,带上耳机,听听看~!
网站死链会影响我们的用户体验和搜索引擎对我们站点的评分(尤其是网站存在已经被做成赌博、色情网站的链接,影响很大),但是网站运营时长长了,就难免会有这样的问题,所以我们可以考虑定期的处理下,我之前分享过一些WordPress死链、外部链接处理的文章,如果你是使用WordPress,就可以直接参考下述的文章去解决:
WordPress/PHP网站实现死链(404链接)自动收集提交处理
WordPress文章失效图片/链接检测插件推荐:Broken Link Checker
如果你的站点程序不是WordPress,就可以参考运行我下面的Python代码来提取然后去删除:
说明下,代码是自己写的,也测试过没问题,但是不同网站的链接情况可能不一样,不确保百分百能用,文档版本则是让GitHub Copilot生成的,原版也有简单的注释,代码不算复杂命名也还合理,就不过多解释了,其实不用文档版应该也好理解的了,软件版本以后有时间再弄了…
把site_url = ‘https://www.linfengnet.com’域名,换成你的即可。
使用前最好是服务器把自己当前的IP加上白名单…
原版代码
# -*- coding: utf-8 -*-
import json
from queue import Queue
from threading import Thread
from urllib.parse import urlparse, urljoin
import requests
from bs4 import BeautifulSoup
checked_links_set = set() # 已经检查过的链接
link_start_dict = dict() # 存储链接的查询状态
class SiteLinkChecker(Thread):
def __init__(self, start_url, link_queue):
super().__init__()
self.start_url = start_url
self.queue = link_queue
self.domain = self.get_domain(start_url)
self.error_link_page = dict()
def run(self):
while True:
try:
if self.queue.empty(): # 如果队列为空,就保存数据到文件 然后退出
self.write_to_file()
break
link = self.queue.get()
global checked_links_set
if link in checked_links_set: # 如果链接已经检查过,就跳过
continue
html_text = self.download_html(link)
checked_links_set.add(link) # 将链接加入到已检查过的链接集合
if not html_text:
continue
soup = self.gent_soup(html_text)
a_tag_dict = self.extract_links(soup) # 提取当前网页所有链接
error_link_list = list()
for a_href, a_text in a_tag_dict.items():
if not a_href.startswith('http'):
a_href = urljoin(self.domain, a_href)
if not self.link_status_check(a_href): # 如果链接状态不是200,
error_link_list.append(a_href)
if self.domain in a_href: # 如果链接是本站的, 就加入到队列继续检查
self.queue.put(a_href)
self.error_link_page[link] = error_link_list
except Exception as e:
with open('请求错误链接.txt', 'a', encoding='utf-8') as f:
f.write(link + str(e) + '\n')
finally:
self.queue.task_done()
def download_html(self, url, timeout=5, retries=3):
"""
下载网页
:param url: 下载链接
:param timeout: 超时时间
:param retries: 超时重试次数
:return: url的HTML内容 str
"""
print(f'正在下载:{url}')
try:
r = requests.get(url, timeout=timeout)
r.raise_for_status()
except requests.Timeout:
if retries > 0:
print('超时重试')
print('retries', retries)
print('timeout', timeout)
self.download_html(url, timeout, retries - 1)
except requests.HTTPError as e:
print(e)
print(url, '下载出错')
else:
r.encoding = 'utf-8'
return r.text
@staticmethod
def gent_soup(html_doc):
"""
生成bs4对象
:param html_doc: html文档
:return: bs4对象
"""
_soup = BeautifulSoup(html_doc, 'html.parser')
return _soup
@staticmethod
def get_domain(url):
"""
提取URL的域名
:param url: URL
:return: 域名
"""
parsed_uri = urlparse(url)
domain = '{uri.scheme}://{uri.netloc}/'.format(uri=parsed_uri)
return domain
# 通过bs4提取所有链接
@staticmethod
def extract_links(soup):
"""
提取所有链接
:param soup: bs4对象
:return:
"""
a_tag_dict = dict()
all_a_tag_list = soup.find_all('a', href=True)
for a_tag in all_a_tag_list:
a_text = a_tag.text
a_text = a_text.strip()
if not a_text:
a_text = '空链接'
href = a_tag.get('href')
a_tag_dict[href] = a_text # 使用链接作为键,文本作为值 避免重复链接
return a_tag_dict
def link_status_check(self, url, timeout=5, retries=3):
"""
下载网页
:param url: 下载链接
:param timeout: 超时时间
:param retries: 超时重试次数
:return:
"""
print(f'正在检查:{url}')
if url in link_start_dict: # 如果链接已经检查过,就直接返回状态
return link_start_dict[url]
if not url.startswith('http'):
return False # 如果链接不是http开头,就直接返回False
try:
r = requests.get(url, timeout=timeout)
r.raise_for_status()
except requests.Timeout:
if retries > 0:
print('超时重试')
print('retries', retries)
print('timeout', timeout)
self.link_status_check(url, timeout, retries - 1)
except requests.HTTPError as e:
print(e)
print(url, '下载出错')
link_start_dict[url] = False
return False
else:
link_start_dict[url] = True
return True
# 写入文件
def write_to_file(self):
"""
将错误的页面和链接写入文件
:return:
"""
# 计算error_link中的键的数量
page_num = len(self.error_link_page)
# 创建一个字典来存储我们的数据
data = {
'page_num': page_num,
'error_link': self.error_link_page
}
with open(f'error_link_page_data.json', 'w') as f:
json.dump(data, f)
if __name__ == '__main__':
site_url = 'https://www.linfengnet.com'
queue = Queue()
queue.put(site_url)
# 创建线程
for i in range(1):
site_link_checker_task = SiteLinkChecker(site_url, queue)
site_link_checker_task.daemon = True # 设置为守护线程
site_link_checker_task.start()
queue.join()简单解释
- 定义一个SiteLinkChecker类,这个类继承了Python的Thread类,使得它可以作为一个线程运行。 在SiteLinkChecker类的初始化方法中,接收两个参数:start_url和link_queue。
- start_url是要检查的网站的起始URL
- link_queue是一个队列,用于存储待检查的链接。
- run方法是线程的入口点。在这个方法中,它会不断地从队列中取出链接并检查。如果链接已经被检查过,就跳过。如果链接有错误,就将其添加到error_link_page字典中。
- download_html方法用于下载给定URL的HTML内容。如果请求超时,它会进行重试。 gent_soup方法用于从HTML内容生成一个BeautifulSoup对象。
- get_domain方法用于从给定的URL中提取域名。
- extract_links方法用于从BeautifulSoup对象中提取所有的链接。
- link_status_check方法用于检查给定URL的状态。如果请求超时,它会进行重试。
- write_to_file方法用于将错误链接和它们的数量写入到一个JSON文件中。
- 脚本的主体部分,首先定义了要检查的网站的URL,然后创建了一个队列,并将起始URL放入队列。然后创建了一个SiteLinkChecker线程,并启动它。最后,使用queue.join()方法等待所有的链接都被检查完毕。
文档版本
# -*- coding: utf-8 -*-
import json
from queue import Queue
from threading import Thread
from urllib.parse import urlparse, urljoin
import requests
from bs4 import BeautifulSoup
# 已经检查过的链接集合
checked_links_set = set()
# 存储链接的查询状态字典
link_start_dict = dict()
class SiteLinkChecker(Thread):
"""
网站链接检查器类,继承自Thread类,用于作为一个线程运行。
属性:
start_url (str): 要检查的网站的起始URL。
queue (Queue): 存储待检查的链接的队列。
domain (str): 要检查的网站的域名。
error_link_page (dict): 存储有错误的链接的字典。
方法:
run(): 线程的入口点,从队列中取出链接并检查。
download_html(url, timeout=5, retries=3): 下载给定URL的HTML内容。
gent_soup(html_doc): 从HTML内容生成一个BeautifulSoup对象。
get_domain(url): 从给定的URL中提取域名。
extract_links(soup): 从BeautifulSoup对象中提取所有的链接。
link_status_check(url, timeout=5, retries=3): 检查给定URL的状态。
write_to_file(): 将错误链接和它们的数量写入到一个JSON文件中。
"""
def __init__(self, start_url, link_queue):
"""
构造方法,初始化SiteLinkChecker对象。
参数:
start_url (str): 要检查的网站的起始URL。
link_queue (Queue): 存储待检查的链接的队列。
"""
super().__init__()
self.start_url = start_url
self.queue = link_queue
self.domain = self.get_domain(start_url)
self.error_link_page = dict()
def run(self):
"""
线程的入口点,从队列中取出链接并检查。如果链接已经被检查过,就跳过。如果链接有错误,就将其添加到error_link_page字典中。
"""
while True:
try:
if self.queue.empty(): # 如果队列为空,就保存数据到文件 然后退出
self.write_to_file()
break
link = self.queue.get()
global checked_links_set
if link in checked_links_set: # 如果链接已经检查过,就跳过
continue
html_text = self.download_html(link)
checked_links_set.add(link) # 将链接加入到已检查过的链接集合
if not html_text:
continue
soup = self.gent_soup(html_text)
a_tag_dict = self.extract_links(soup) # 提取当前网页所有链接
error_link_list = list()
for a_href, a_text in a_tag_dict.items():
if not a_href.startswith('http'):
a_href = urljoin(self.domain, a_href)
if not self.link_status_check(a_href): # 如果链接状态不是200,
error_link_list.append(a_href)
if self.domain in a_href: # 如果链接是本站的, 就加入到队列继续检查
self.queue.put(a_href)
self.error_link_page[link] = error_link_list
except Exception as e:
with open('请求错误链接.txt', 'a', encoding='utf-8') as f:
f.write(link + str(e) + '\n')
finally:
self.queue.task_done()
def download_html(self, url, timeout=5, retries=3):
"""
下载给定URL的HTML内容。如果请求超时,它会进行重试。
参数:
url (str): 要下载HTML内容的URL。
timeout (int, 可选): 请求的超时时间,默认为5。
retries (int, 可选): 请求超时时的重试次数,默认为3。
返回:
str: URL的HTML内容。
"""
print(f'正在下载:{url}')
try:
r = requests.get(url, timeout=timeout)
r.raise_for_status()
except requests.Timeout:
if retries > 0:
print('超时重试')
print('retries', retries)
print('timeout', timeout)
self.download_html(url, timeout, retries - 1)
except requests.HTTPError as e:
print(e)
print(url, '下载出错')
else:
r.encoding = 'utf-8'
return r.text
@staticmethod
def gent_soup(html_doc):
"""
从HTML内容生成一个BeautifulSoup对象。
参数:
html_doc (str): HTML内容。
返回:
BeautifulSoup: 从HTML内容生成的BeautifulSoup对象。
"""
_soup = BeautifulSoup(html_doc, 'html.parser')
return _soup
@staticmethod
def get_domain(url):
"""
从给定的URL中提取域名。
参数:
url (str): 要提取域名的URL。
返回:
str: URL的域名。
"""
parsed_uri = urlparse(url)
domain = '{uri.scheme}://{uri.netloc}/'.format(uri=parsed_uri)
return domain
@staticmethod
def extract_links(soup):
"""
从BeautifulSoup对象中提取所有的链接。
参数:
soup (BeautifulSoup): 要提取链接的BeautifulSoup对象。
返回:
dict: 包含链接和它们的文本的字典。
"""
a_tag_dict = dict()
all_a_tag_list = soup.find_all('a', href=True)
for a_tag in all_a_tag_list:
a_text = a_tag.text
a_text = a_text.strip()
if not a_text:
a_text = '空链接'
href = a_tag.get('href')
a_tag_dict[href] = a_text # 使用链接作为键,文本作为值 避免重复链接
return a_tag_dict
def link_status_check(self, url, timeout=5, retries=3):
"""
检查给定URL的状态。如果请求超时,它会进行重试。
参数:
url (str): 要检查状态的URL。
timeout (int, 可选): 请求的超时时间,默认为5。
retries (int, 可选): 请求超时时的重试次数,默认为3。
返回:
bool: 如果URL的状态是OK,返回True,否则返回False。
"""
print(f'正在检查:{url}')
if url in link_start_dict: # 如果链接已经检查过,就直接返回状态
return link_start_dict[url]
if not url.startswith('http'):
return False # 如果链接不是http开头,就直接返回False
try:
r = requests.get(url, timeout=timeout)
r.raise_for_status()
except requests.Timeout:
if retries > 0:
print('超时重试')
print('retries', retries)
print('timeout', timeout)
self.link_status_check(url, timeout, retries - 1)
except requests.HTTPError as e:
print(e)
print(url, '下载出错')
link_start_dict[url] = False
return False
else:
link_start_dict[url] = True
return True
def write_to_file(self):
"""
将错误链接和它们的数量写入到一个JSON文件中。
"""
# 计算error_link中的键的数量
page_num = len(self.error_link_page)
# 创建一个字典来存储我们的数据
data = {
'page_num': page_num,
'error_link': self.error_link_page
}
with open(f'error_link_page_data.json', 'w') as f:
json.dump(data, f)
if __name__ == '__main__':
site_url = 'https://www.linfengnet.com/'
queue = Queue()
queue.put(site_url)
# 创建线程
for i in range(1):
site_link_checker_task = SiteLinkChecker(site_url, queue)
site_link_checker_task.daemon = True # 设置为守护线程
site_link_checker_task.start()
queue.join()
```
这段代码的主要功能是检查一个网站中所有链接的状态,并将有错误的链接和它们的数量写入到一个JSON文件中。结果预览
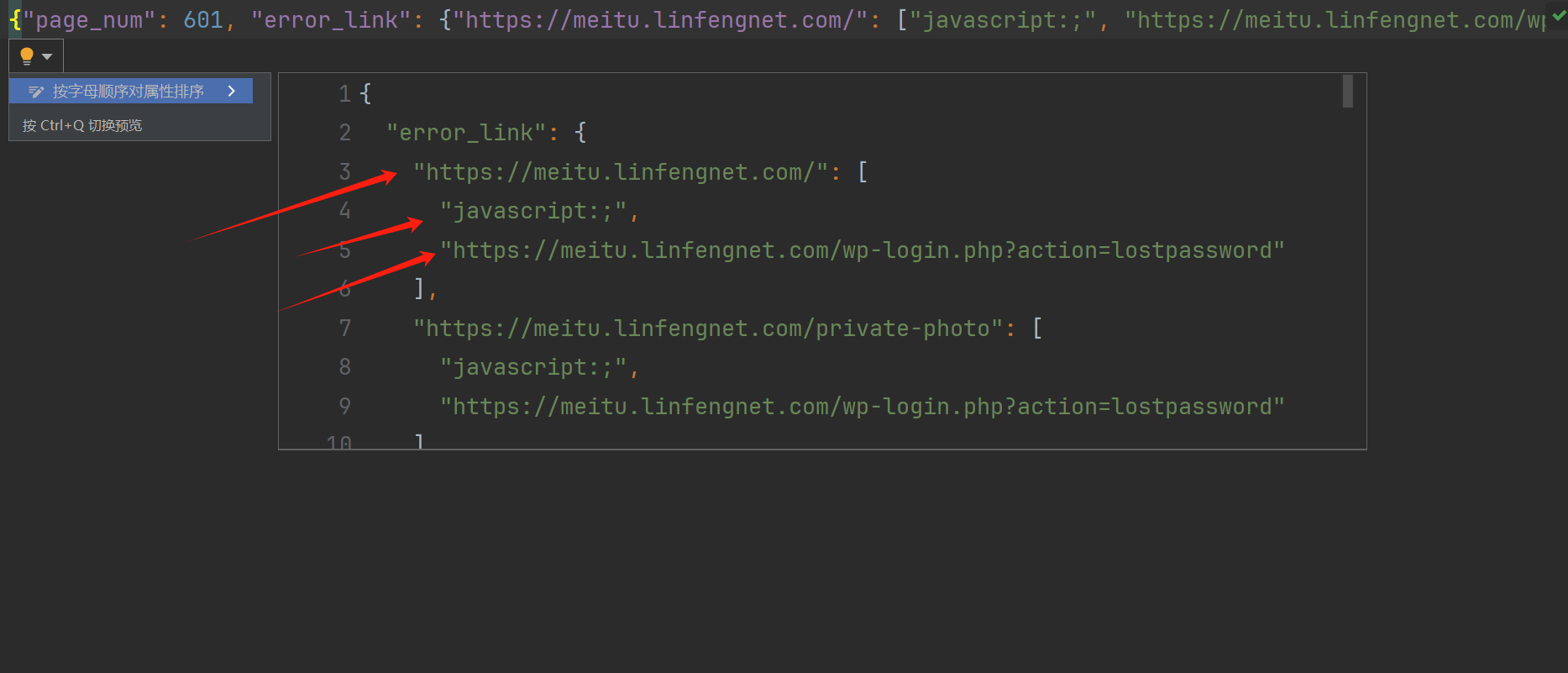
运行完成后,会把结果保存为一个json文件:
代码完善
如果你想要比较完美的处理,按我的经验的上述的代码还可以从如下地方优化一下:
- 去除JavaScript这类常见的无效链接。
- 只提取文章内容部分(全站页头页脚通用的话)。
- 把失效链接对应的文章一起保存到json文件,更加方便寻找去除。
- 如果一个链接已经变成赌博网站之类的内容了,上述代码是无法解决的,可以考虑检查一下链接文字和请求后的标题是否一致或者相关来判断…
- 集思广益,欢迎大家一起沟通完善…
- …..
最后再附带一下之前分享的Python推荐资料和文章,感兴趣的小伙伴可以去学习。

