
在编写爬虫的时候,如果遇见参数图片化的情况的(例如登录验证码),就需要对图片验证码进行识别,我们就可以使用pytesseract。
pytesseract简介
pytesseract是一款用于光学字符识别(OCR)的python工具,即从图片中识别出和“读取”其中嵌入的文字。
底层使用的是Google的Tesseract-OCR 引擎(Tesseract是一个开源文本识别 (OCR) 引擎(注意:这里是引擎,而不是Python库),可在 Apache 2.0 许可下使用。主要版本5是当前的稳定版本,并于2021年11月30日从5.0.0版本开始。Tesseract可以直接通过命令行使用,或者(对于程序员)通过使用API(提供的调用接口,如:C、Python等)从图像中提取打印文本。它支持多种语言。)
Tesseract还可以自己训练,使其获得更强的图像转换文本的能力。
参考博客:
更多Tesseract相关的内容,可以访问Tesseract的GitHub,下方有链接。
而pytesseract是对Tesseract-OCR的一层封装,同时也可以单独作为对Tesseract引擎的调用脚本,支持使用PIL库(Python Imaging Library)读取各种图片文件类型,包括jpeg、png、gif、bmp、tiff等其它格式。作为脚本使用时,pytesseract将打印识别出的文字,而不是将其写入文件。
项目GitHub地址:
pytesseract:
https://github.com/madmaze/pytesseract/
Tesseract:
https://github.com/tesseract-ocr/tesseract
安装pytesseract
pip install pytesseract注意:
Python的版本要求是python 3.x。
使用需要安装谷歌的OCR识别引擎Tesseract-OCR。
前面简介中,已经提到pytesseract是基于Google的Tesseract-OCR,所以我们需要安装好Tesseract-OCR来进行使用。
安装Tesseract-OCR
我这里以安装Tesseract-OCR的当前最新5.2.0版为例,网上说5.0版本准确率较之前的版本有很大提升。但是我安装这个版本后,发现还不如以前使用的4.0版本(所以建议你下载4.0版本的进行安装)….
下载Tesseract-OCR
- 官方文档:https://github.com/tesseract-ocr/tessdoc
- 语言包地址:https://github.com/tesseract-ocr/tessdata
- 下载地址:https://digi.bib.uni-mannheim.de/tesseract/ (这个地址可是我找了很久才找到的, 各个版本的都有)
由于国内特殊网络原因,你在上述的地址下载可能很慢,我这里提供了一个百度云下载地址:
tesseract-ocr-w64-setup-v5.2.0.20220712
sihu复制
tesseract-ocr-setup-4.00.00dev
n4ep复制
当你下载好后,直接双击打开进行安装
安装流程
软件没有中文,直接使用英文安装,点击OK、Next就行
用户协议,点击 I Agree 即可。
为计算机中的任何用户安装还是当前用户,默认是任何用户。可以直接点击:Next
组件选择页面,前面的保持默认,后面两个选项是安装相关的组件和语言数据,如果有中文识别的需求,可以把:Han Simplified script、Han Simplified vertical script等Han、Chinese等开头的选项都勾选上。
也可以直接点击:Next 进行下一步。
选择安装路径。自己设定就行。然后点击:Next
设置在开始菜单中的名称,可以直接点击 install,如果不需要就点击左下角的Do not create shortcuts
等待安装完成
点击 Next
安装完成,点击 Finish 即可。
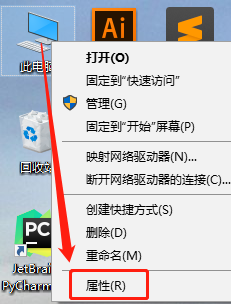
配置环境变量
右键点击此电脑–属性–高级系统设置–环境变量–系统变量–Path
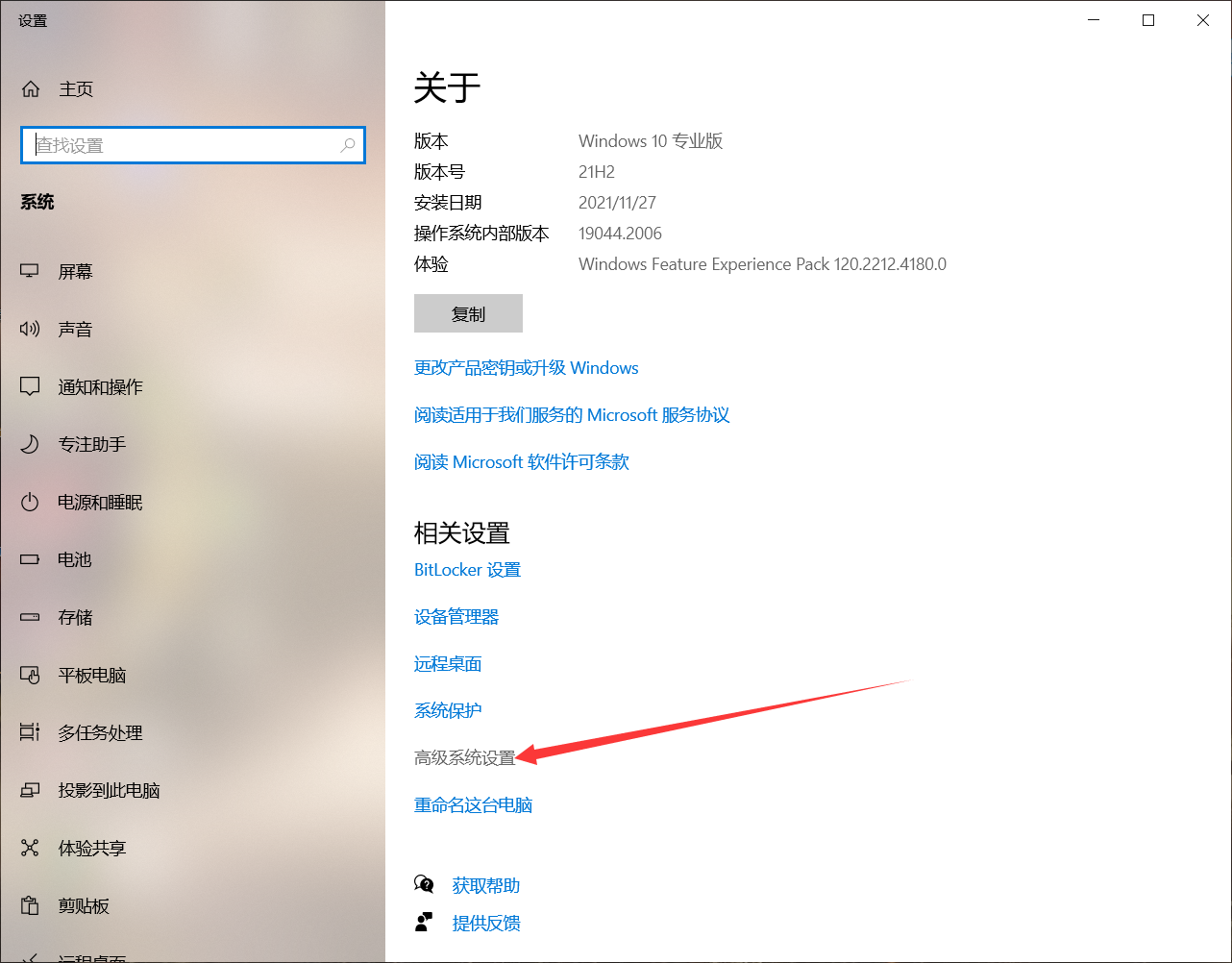
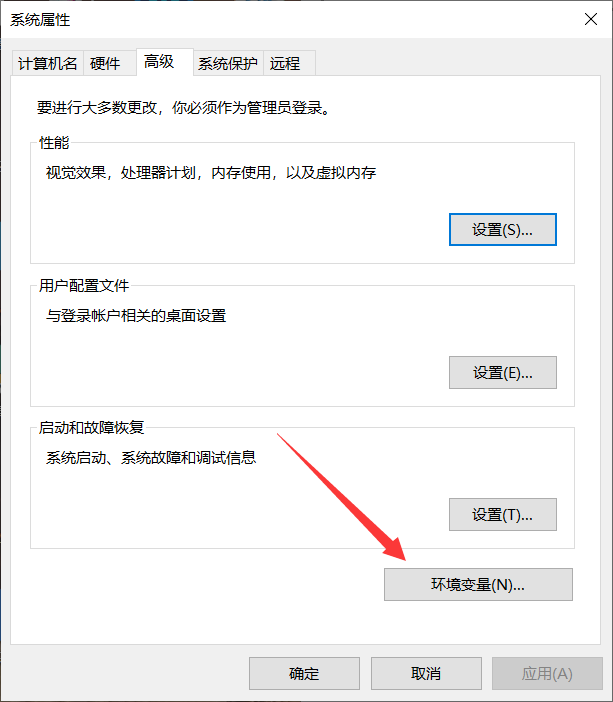
找到系统变量Path,点击编辑,将 Tesseract-OCR 的安装目录添加进去:
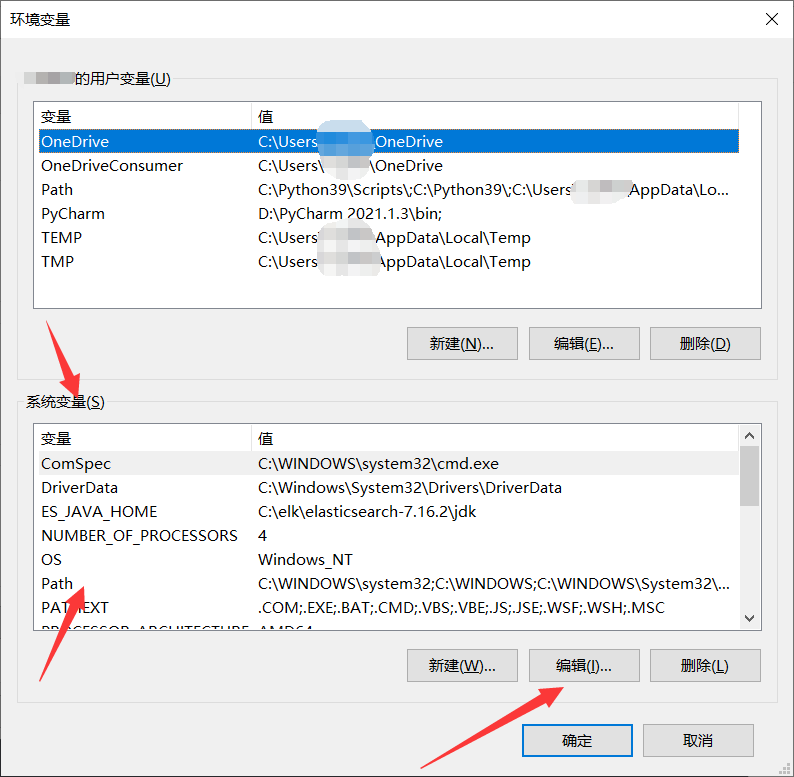
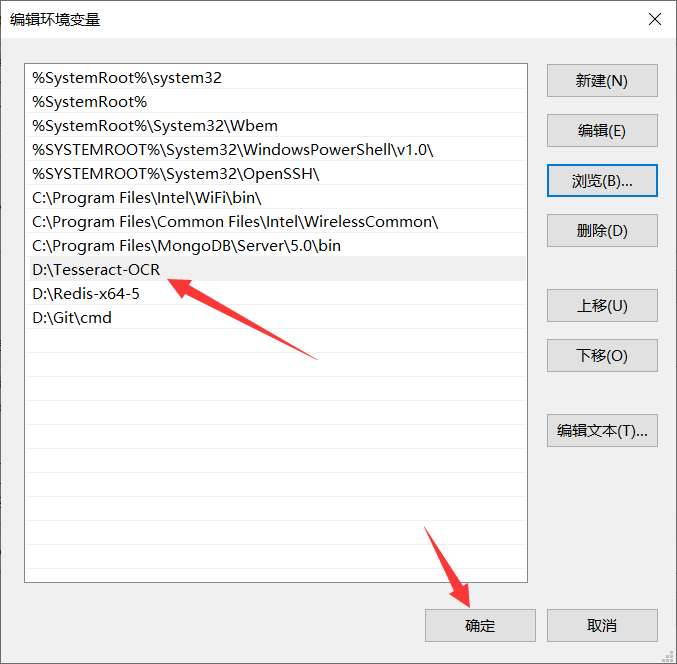
新建系统变量 : TESSDATA_PREFIX
变量值为Tesseract-OCR的安装目录下tessdata 文件夹的路径
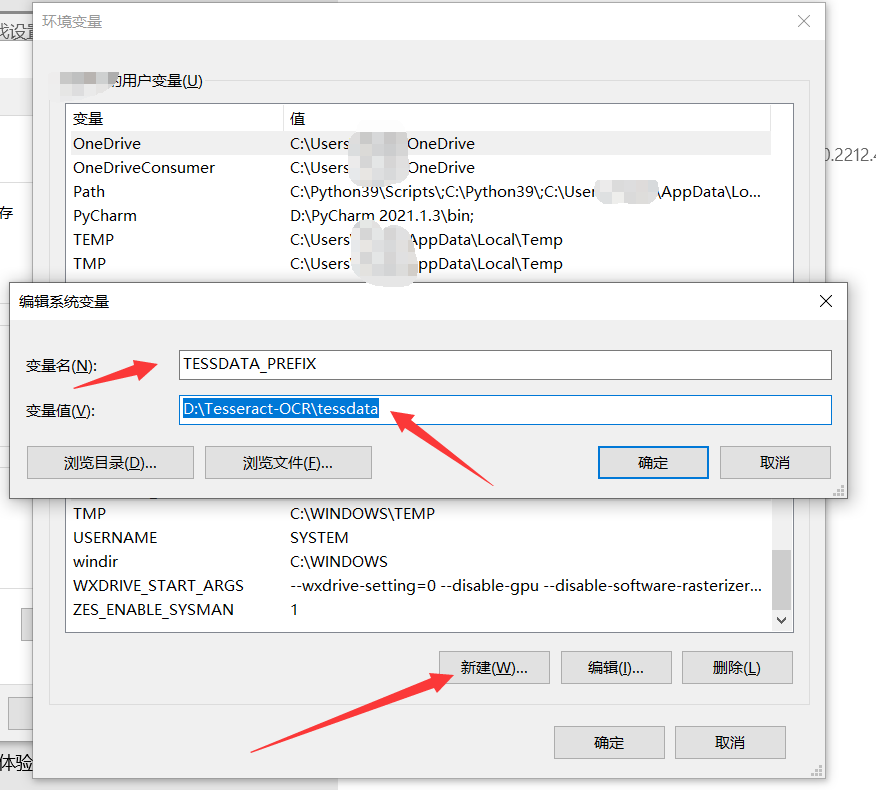
验证和简单实用
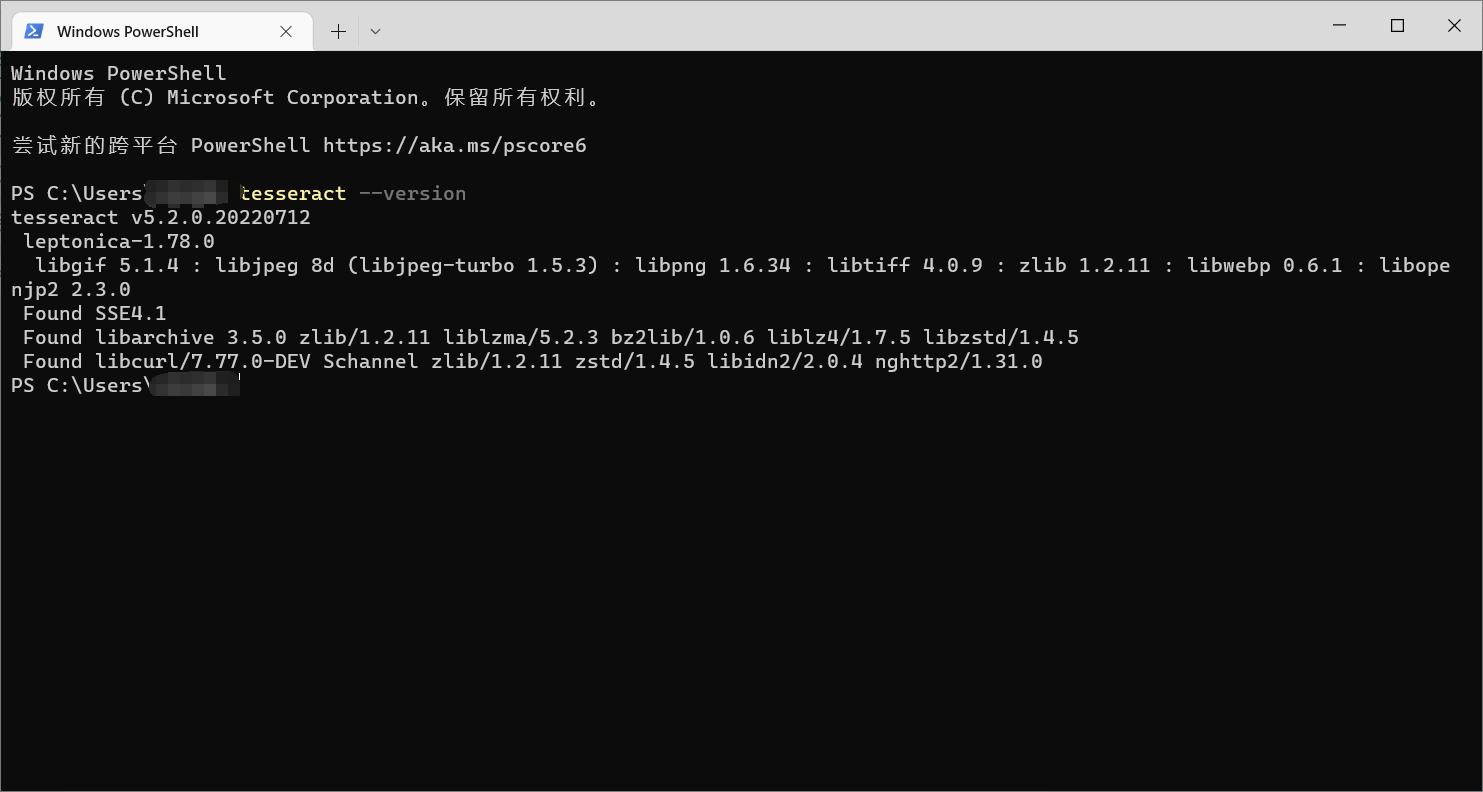
安装后记得重启奥,然后进入cmd,输入下面的命令查看版本,正常运行则安装成功:
tesseract --version出现类型如下提示 则代表成功了
可以直接打开cmd 然后输入如下命令进行简单实用:
tesseract 图片路径 输出文件例如:
tesseract C:\xxxx.png C:\file-namepytesseract简单使用
下面实例中使用了 PILLOW , 如果没安装PILLOW 可以先安装下。
pip install PILLOWpytesseract image_to_string
在pytesseract库中,提供了image_to_string函数将图像转换成字符串,具体如下:
image_to_string(image, lang=None, boxes=False, config=None)
上述函数用于在指定的图像上运行tesseract,首先将图像写入到磁盘,然后在图像上运行tesseract命令进行识别读取,最后删除临时的文件。
image_to_string参数
image表示图像
lang表示语言
默认使用英文
如果boxes设为True,那么“batch.nochop makebox”被添加到tesseract调用中;
如果设置了config,则配置会添加到命令中,例如config =“ – psm 6”。
image_to_string 实例
下述代码是以一个thinkcmf程序的后台验证码地址为例的,为了保护网站,图片地址我去除了。你可以自己用自己的,或者本地用图片做测试。
# -*- coding: utf-8 -*-
import pytesseract
from PIL import Image
import requests
# 远程获取图片
url = 'https://xxxxxxxx/new_captcha.html?height=32&width=150&font_size=18'
# stream=True表示 以二进制数据流的方式获取
re_img = requests.get(url, stream=True)
# 获取图片对象
img_data = Image.open(re_img.raw)
print(img_data)
# 本地读取图片
# img_data = Image.open("file_name.png")
# 使用 OCR 识别图片内容
Verification_Code = pytesseract.image_to_string(img_data)
print(Verification_Code)直接使用的话,只能识别一些非常简单,没任何干扰的图片,我们可以考虑对图片进行二值化处理,再进行识别。
图像二值化
图像二值化( IMAGE BINARIZATION)就是将图像上的像素点的灰度值设置为0或255,也就是将整个图像呈现出明显的黑白效果的过程。
在数字图像处理中,二值图像占有非常重要的地位,图像的二值化使图像中数据量大为减少,从而能凸显出目标的轮廓。
图像二值化 – 百度百科
# -*- coding: utf-8 -*-
import pytesseract
from PIL import Image
captcha = Image.open('img_name.png')
# 没二值化的结果
result = pytesseract.image_to_string(captcha)
print(result)
# 图片转灰度处理
captcha = captcha.convert('L')
# # 阈值 控制二值化程度,不能超过256
threshold = 200
table = []
for i in range(256):
if i < threshold:
table.append(0)
else:
table.append(1)
# 图片二值化,convert('1')
captcha = captcha.point(table, '1')
# 二值化的结果
result = pytesseract.image_to_string(captcha)
print(result)
如果出现错误,一般是系统变量设置的问题:
解决办法一:根据安装Tesseract软件的步骤配置环境变量,设置好即可。
解决方法二:在代码中添加相关变量参数:
import pytesseract
from PIL import Image
pytesseract.pytesseract.tesseract_cmd = 'D:/Program Files (x86)/Tesseract-OCR/tesseract.exe'
tessdata_dir_config = '--tessdata-dir "D:/Program Files (x86)/Tesseract-OCR/tessdata"'
image = Image.open("code.png")
code = pytesseract.image_to_string(image, config=tessdata_dir_config)
print(code)到这里就结束了,部分内容参考:

